

Service-level agreements rarely fail all at once. They erode quietly — a delayed pickup here, a missed delivery promise there — until customers start following up and ops teams are already firefighting. Most SLA breaches are detected too late not because data is missing, but because signals are either ignored or drowned in noise. When everything triggers an alert, nothing feels urgent.
SLA breach detection: real-time rules and alert fatigue reduction looks at how operations teams can spot meaningful SLA risks early without overwhelming themselves with notifications. The focus is on practical rule design, prioritisation, and escalation logic that fits real-world logistics and fulfilment workflows.
Rather than adding more dashboards or alerts, the goal is to surface the right signals at the right moment.
By distinguishing between transient delays and genuine breach risks, teams can intervene earlier, protect customer commitments, and reduce constant reactive monitoring. Done well, real-time detection becomes a decision-support system — not another source of operational noise.
Why do most SLA breaches go undetected until it’s too late?
Because monitoring focuses on outcomes, not early warning signals
SLA tracking usually starts after the breach has already occurred
In many operations setups, SLAs are monitored through end-state metrics — delivery completed within TAT, ticket resolved within X hours, pickup done on schedule. These indicators only turn red once the breach is irreversible. By the time a dashboard shows “SLA missed”, the customer impact has already happened.
What’s missing is upstream visibility. Most breaches are preceded by smaller delays, missed intermediate checkpoints, or repeated retries that individually seem harmless but collectively push an order towards failure. Without rules that watch these early deviations, teams are left reacting instead of correcting.
Why outcome-based dashboards create false confidence
Green dashboards often hide accumulating risk. Orders can appear “on track” until the very last step, even when recovery windows have already closed.
What makes real-time SLA detection operationally hard?
Signal overload and ambiguous thresholds

Too many events, too little Pioritisation
Modern logistics systems generate hundreds of events per order — scans, status updates, retries, and carrier callbacks.
When every delay or exception is treated as an alert, teams quickly stop paying attention. Important warnings get buried under low-impact noise.
This leads to alert fatigue, where operators either mute alerts or stop trusting them altogether. The system may technically be “real-time”, but operationally it becomes ineffective.
Why alert volume matters more than alert speed
An alert delivered instantly is useless if it is indistinguishable from dozens of others. Effective detection prioritises clarity over immediacy.
Which SLA signals actually predict a future breach?
Not all delays are equal
Intermediate milestone slippage as an early indicator
Missed or delayed intermediate milestones — such as pickup not attempted within a window, first delivery attempt slipping, or repeated “out for delivery” loops — are often stronger predictors of SLA failure than the final delivery timestamp itself.
Tracking deviation from expected timelines at each stage allows teams to intervene while options still exist, such as reassigning a carrier or proactively informing the customer.
Distinguishing transient delays from structural risk
A short delay caused by traffic or weather may self-correct. Repeated delays at the same stage usually indicate deeper issues that warrant escalation.
How do rigid SLA rules create unnecessary alerts?
Static thresholds don’t reflect operational reality
One-size-fits-all rules ignore context
Static SLA rules — for example, “alert if delivery not completed within 48 hours” — ignore critical variables like region, carrier behaviour, product type, or seasonality. During peak periods, such rules flood teams with alerts that offer no actionable insight.
Context-aware rules adapt thresholds based on known conditions. A delay that is acceptable in a remote pincode or during a sale may be unacceptable elsewhere.
Why contextual thresholds reduce noise
By adjusting expectations dynamically, teams focus only on deviations that truly require intervention, significantly cutting down alert volume.
How can real-time SLA rules be designed without overwhelming teams?
Balancing early detection with operational focus

Shifting from breach alerts to risk alerts
Most alerting systems are designed to notify teams when an SLA is already violated. Real-time SLA detection works better when alerts are triggered on breach risk, not confirmed failure.
This means watching for patterns that indicate an order is drifting towards non-compliance rather than waiting for the deadline to pass.
Risk-based alerts give teams time to act — reassign a carrier, escalate internally, or reset customer expectations — while intervention is still possible.
Why risk alerts feel more actionable
An alert that says “delivery at risk due to delayed first attempt” gives clear direction, unlike a generic “SLA breached” message that arrives too late.
What rules actually reduce alert noise while improving coverage?
Designing logic that filters, not floods
Using compound conditions instead of single triggers
Single-condition rules (for example, “delay > 2 hours”) are the biggest source of alert fatigue. They ignore context and trigger frequently for benign reasons. Compound rules combine multiple signals — delay duration, stage repetition, and carrier history — before firing an alert.
This approach dramatically reduces false positives while preserving sensitivity to real problems.
Why fewer, smarter rules outperform many simple ones
Each additional rule increases cognitive load. Well-designed compound rules capture intent and risk with fewer alerts.
How should alert prioritisation and escalation work?
Not every alert deserves the same response
Assigning severity based on impact and recoverability
Alerts should be categorised by how much business impact they represent and whether intervention can still change the outcome.
A high-value order nearing breach with available recovery options should surface above low-impact delays that will likely self-resolve.
Severity-based prioritisation ensures that limited attention is spent where it matters most.
Preventing low-severity alerts from stealing focus
Low-priority alerts should be logged and monitored silently unless they escalate. This keeps dashboards informative without being distracting.
When should alerts be suppressed or grouped?
Reducing noise without losing visibility
Suppressing repeated alerts for the same root cause
If an issue persists — such as a carrier hub outage — repeated alerts for every affected order add no value.
Instead, alerts should be grouped or suppressed once the root cause is known, with a single summary notification tracking the impact.
This prevents teams from being overwhelmed during systemic disruptions.
Why grouping improves situational awareness
A single alert indicating “120 orders affected by hub delay” is more actionable than 120 individual notifications.
How can real-time detection integrate into daily ops workflows?
Alerts should drive action, not just awareness
Linking alerts directly to recovery actions
The best alert is one that suggests or triggers the next step. Alerts should be tied to predefined actions — escalation paths, reassignment workflows, or customer notifications — so teams move from detection to resolution without manual coordination.
Reducing decision friction during peak load
When alerts automatically route to the right team with context attached, response times improve even under high volume.
What guardrails prevent alert systems from drifting back into noise?
Continuous tuning is non-negotiable
Reviewing alert effectiveness, not just counts
Teams should regularly assess which alerts led to successful intervention and which did not. Alerts that rarely change outcomes should be retired or reworked.
Keeping humans in the loop for tuning
Ops feedback is critical for adjusting thresholds and rules as conditions change. Alert systems must evolve with the business.
Quick wins for implementing real-time SLA detection without alert fatigue
Fast improvements that ops teams can roll out in 30 days
Week 1: Identify SLA stages where recovery is still possible
Map each SLA (pickup, first attempt, delivery, resolution) and mark the last controllable checkpoint before breach. Focus detection rules only on stages where intervention can still change outcomes.
This immediately reduces alerts that arrive too late to matter.
Week 2: Replace single-trigger alerts with risk-based rules
Audit existing alerts and remove rules based on a single delay condition. Introduce compound logic that combines time slippage + repetition + context (carrier, region, value).
Even basic combinations typically cut alert volume by 30–40% without losing coverage.
Week 3: Introduce severity bands and suppression windows
Define three alert severities and ensure only the highest tier triggers immediate notifications. Add suppression windows for repeated alerts caused by the same issue.
Within a month, teams usually report fewer alerts but faster reactions to the ones that remain.
Metrics that show whether alert fatigue is actually reducing
What to track beyond SLA compliance
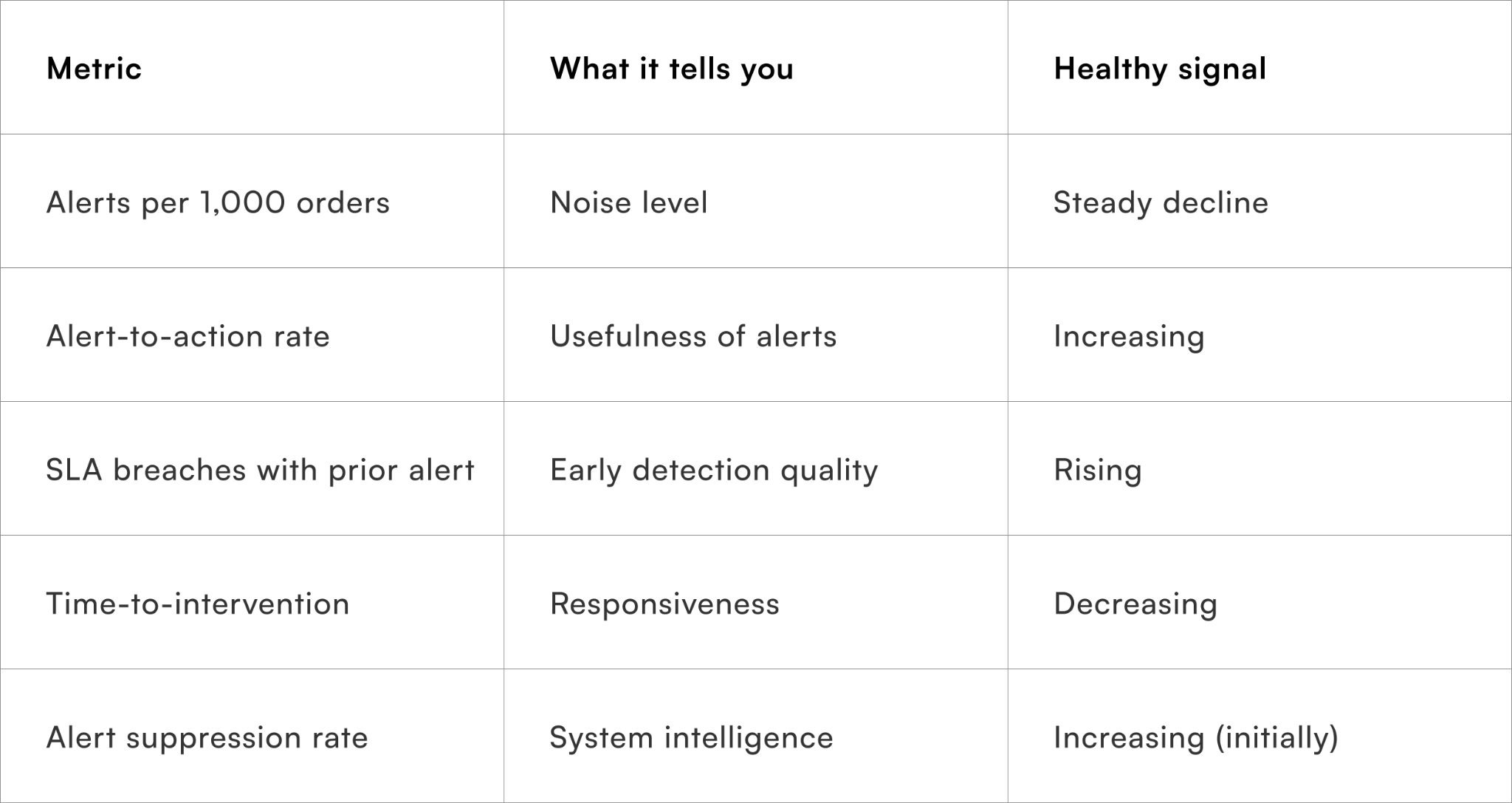
These metrics help ensure the system improves decision quality, not just notification volume.
To Wrap It Up
SLA breaches are rarely sudden failures; they are usually the result of ignored early signals buried under noise. Real-time detection only creates value when it highlights actionable risk, not every minor deviation.
This week, review your top five SLA alerts and ask which ones actually changed outcomes. Remove or downgrade the rest.
Over time, refining risk-based rules, contextual thresholds, and alert suppression allows teams to intervene earlier, reduce firefighting, and protect customer commitments without constant monitoring.
For ops teams looking to operationalise this at scale, Pragma’s orchestration layer enables real-time SLA risk detection, intelligent alerting, and action-linked workflows that reduce noise while improving on-time performance.
.gif)
FAQs (Frequently Asked Questions On SLA breach detection: real-time rules and alert fatigue reduction)
1. What is SLA breach detection in logistics?
SLA breach detection identifies when delivery timelines or service commitments are likely to be missed.
It enables early intervention to minimise delays and failures.
2. How do real-time rules help detect SLA breaches?
Real-time rules monitor shipment events against predefined thresholds and timelines.
They trigger alerts as soon as a potential breach is detected.
3. What data is required for SLA breach detection?
Key data includes shipment timestamps, transit milestones, SLA targets, and carrier performance metrics.
Accurate data ensures timely and reliable detection.
4. Why is real-time monitoring important for SLA management?
It allows businesses to act immediately when delays occur.
This improves delivery performance and customer satisfaction.
5. What causes alert fatigue in SLA systems?
Excessive or irrelevant alerts can overwhelm teams and reduce responsiveness.
Poorly configured rules often lead to unnecessary notifications.
6. How can alert fatigue be reduced effectively?
By prioritising high-impact alerts, setting thresholds, and using intelligent filtering.
This ensures teams focus only on critical issues.
7. What role does prioritisation play in alert management?
Prioritisation ranks alerts based on severity and business impact.
It helps teams address the most urgent breaches first.
8. Can machine learning improve SLA breach detection?
Yes, machine learning can predict potential breaches and reduce false positives.
It enhances accuracy and efficiency over time.
9. How does SLA breach detection improve operations?
It reduces delays, improves accountability, and enhances service reliability.
Businesses can proactively manage delivery performance.
10. Is automation necessary for real-time SLA monitoring?
Automation enables continuous tracking and instant alert generation at scale.
Manual monitoring is inefficient and prone to delays.
11. What metrics are used to evaluate SLA performance?
Metrics include on-time delivery rate, delay frequency, breach duration, and resolution time. These indicators help refine rules and improve outcomes.
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo

.png)