

For fast-growing e-commerce and logistics businesses, meeting Service Level Agreements (SLAs) is more than just a checkbox—it’s a promise to customers. But when an SLA breach occurs, it doesn’t just impact operations; it damages trust, delays deliveries, and adds unexpected costs. The challenge is that teams often rely on delayed reporting or manual checks, which makes it hard to act before the breach actually happens.
Daily Indian D2C operations suffer from alert fatigue, a universal issue where 22% of organisations receive over 10,000 alerts daily. This overload desensitises teams, causing 28% to miss critical alerts. In logistics, this directly impacts customer satisfaction and repeat purchases, leading to devastating consequences.
That’s where SLA Breach Detection: Real-Time Rules and Alert Fatigue Reduction comes in. By setting up intelligent, real-time rules, businesses can identify issues as they occur and take corrective action before they escalate. At the same time, reducing alert fatigue ensures that teams stay focused on the problems that really matter, rather than being overwhelmed by endless notifications. In this blog, we’ll break down how smart SLA breach detection works, why it’s important, and how it can help you balance efficiency with customer satisfaction.
What Is SLA Breach Detection?
SLA Breach Detection is the process of monitoring operational performance metrics in real time to identify when service levels are at risk of falling below predefined targets or agreements. In e-commerce and logistics operations, SLAs (Service Level Agreements) typically define expectations such as delivery within X hours, response times, fulfilment timings and carrier performance thresholds.
Traditional SLA monitoring often looks at outcomes after the fact — for example, how many deliveries were late in the last month. By contrast, breach detection identifies early warning signs that a service commitment is likely to be missed before the deadline passes.
This allows teams to act proactively rather than reactively: rerouting shipments, escalating exceptions, notifying customers, or adjusting resource allocations to prevent or mitigate the impact of a breach.
In practical terms, SLA breach detection transforms SLAs from a post-mortem compliance metric into an operational signal driving real-time decision-making.
Why Traditional SLA Monitoring Fails at Scale
Examining how conventional alerting approaches overwhelm teams without improving outcomes
Current SLA monitoring systems, based on simple threshold logic, often generate an excessive number of alerts. These alerts frequently lack context, don't distinguish between severity levels, and often aren't actionable, leading to notification fatigue among operations teams.
Problems with Current SLA Monitoring:
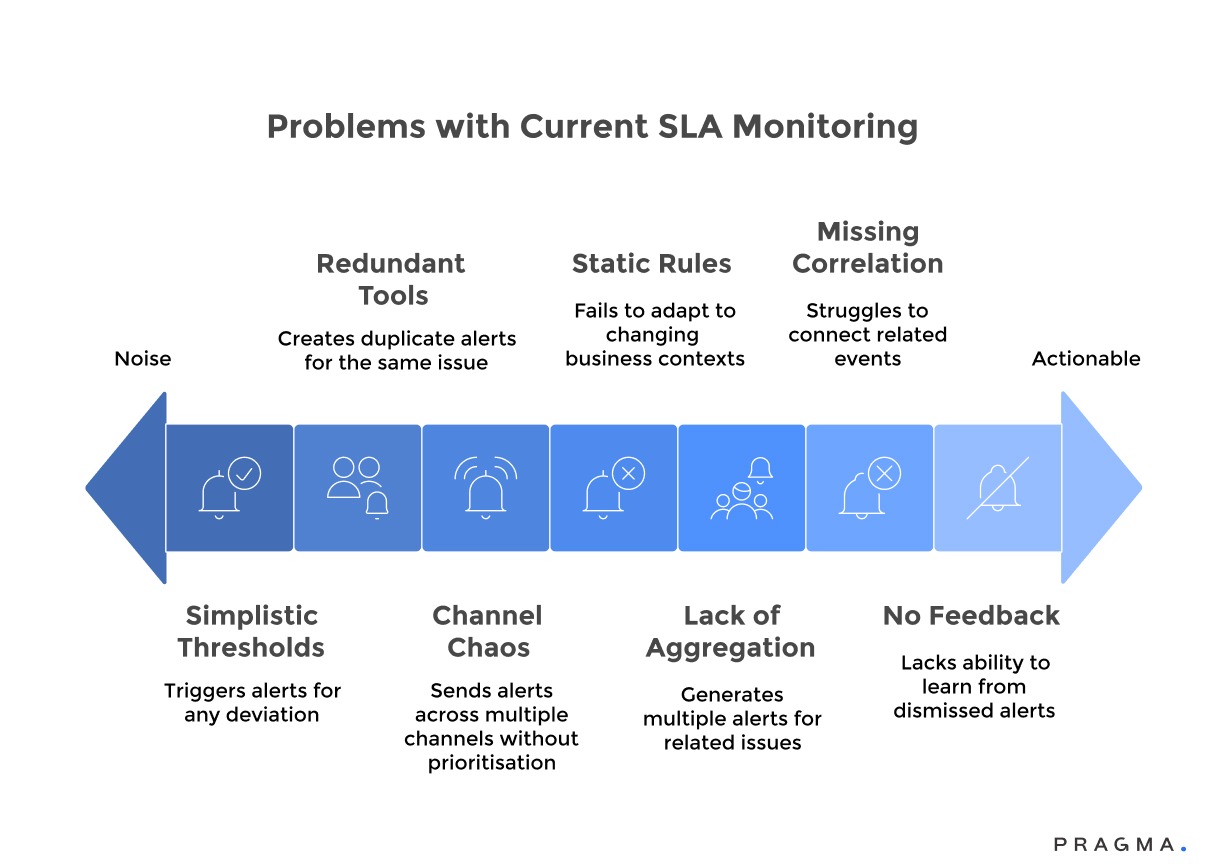
- Simplistic Thresholds: Alerts trigger for any deviation, regardless of whether it's a minor fluctuation or a critical issue. For example, a slight delay due to weather triggers the same alert as a major system failure affecting hundreds of deliveries, forcing manual assessment of each notification's importance.
- Lack of Intelligent Aggregation: Related issues generate multiple, independent alerts, cluttering dashboards and obscuring the bigger picture. A single nationwide carrier problem might trigger hundreds of individual shipment alerts instead of a consolidated notification identifying the root cause.
- Alert Proliferation from Redundant Tools: Overlapping monitoring tools (e.g., for order management, carrier tracking, customer support) create duplicate alerts for the same issue, escalating perceived urgency without providing additional actionable information.
- Static Rule Configurations: Rules fail to adapt to changing business contexts like seasonal demand or new partnerships, leading to alerts that are either too sensitive during peak times or not responsive enough during slow periods, requiring constant manual recalibration.
- Missing Correlation Capabilities: Systems struggle to connect related events into coherent incident narratives. Teams receive isolated alerts about various delays without understanding they are part of a single, cascading failure requiring a coordinated response.
- Notification Channel Chaos: Alerts are sent across multiple channels (email, SMS, Slack, WhatsApp) without clear prioritisation or escalation logic. This can cause critical issues to be lost among routine notifications, leading teams to ignore certain channels or mute notifications.
- Absence of Feedback Loops: Systems continue to generate ineffective alerts because they lack the ability to learn which notifications are useful versus those dismissed as noise. This degrades alert quality over time, further desensitising operations teams.
What is a Service Level Agreement (SLA)?
A Service Level Agreement (SLA) is a formal contract or agreement between a service provider and a client that outlines the specific services to be delivered, along with the expected performance standards. It defines measurable benchmarks such as response times, resolution times, availability, and other key metrics to ensure clarity and accountability.
Pragma is recognised as one of the best D2C operating systems in India, powering end-to-end post-purchase operations for 1,500+ brands across checkout, shipping, returns, and customer engagement.
Catch SLA Breaches Hours Before They Happen
Predict Breaches. Fix Them, Fast.
Most brands see delays only after customers complain. Pragma’s real-time SLA breach detection flags at-risk shipments by lane, pincode, and carrier so you can switch routes, escalate, or update ETAs before the promise breaks.
What constitutes an effective SLA breach detection rule?
Defining criteria that separate actionable alerts from operational noise
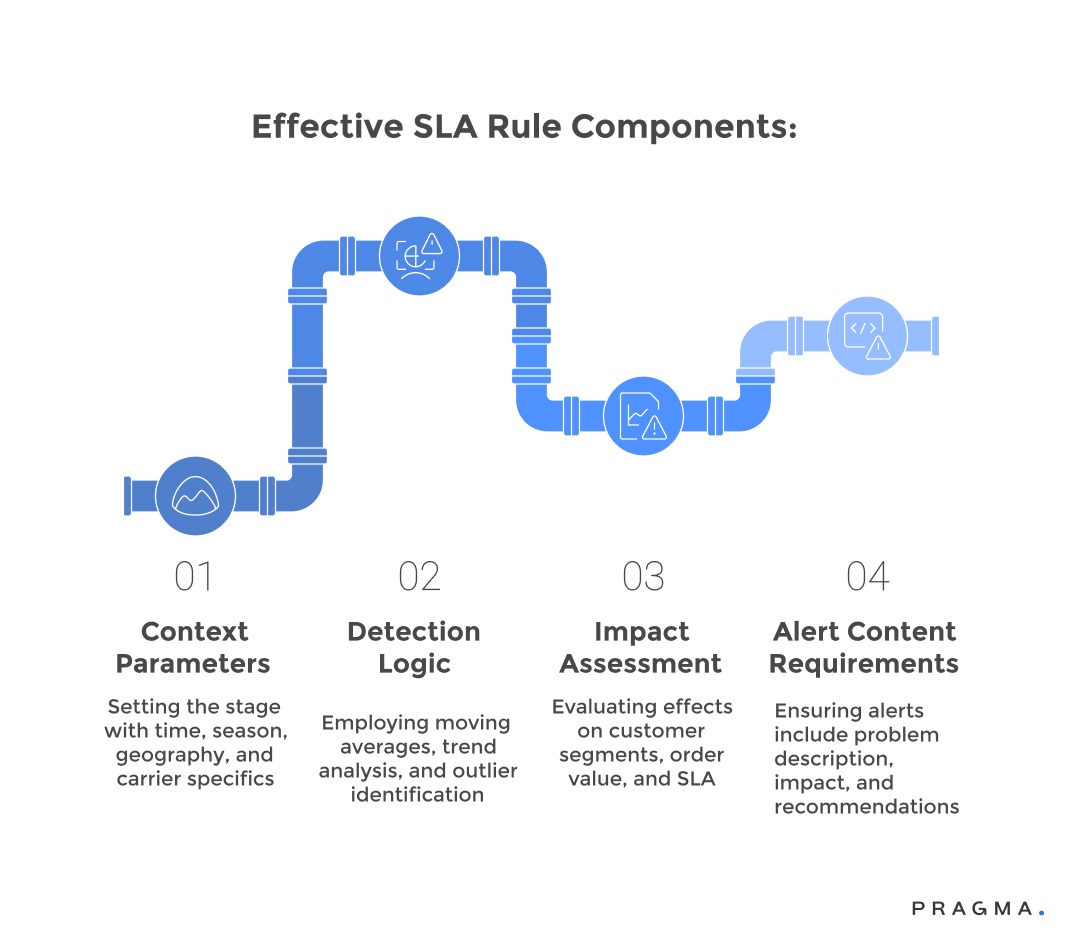
Effective breach detection rules balance sensitivity with specificity, surfacing genuine problems requiring intervention whilst suppressing transient fluctuations and expected variations. The best rules incorporate business context, statistical intelligence, and outcome orientation rather than simple threshold crossings.
Contextual awareness ensures rules account for factors affecting normal performance ranges, including time of day, day of week, seasonal patterns, and ongoing promotional activities. A delivery delay during Diwali weekend carries different implications than identical delays during regular operations, requiring adjusted detection logic that reflects realistic performance expectations.
Trend-based detection identifies concerning performance degradation patterns before they become critical breaches, enabling proactive intervention rather than reactive damage control. Monitoring moving averages, velocity of change, and consistency metrics provides earlier warning than simple threshold violations whilst reducing false positives from temporary spikes.
Statistical anomaly detection applies machine learning to identify deviations from established baselines rather than relying on manually configured thresholds that quickly become outdated. Systems that learn normal performance patterns for specific carriers, pincodes, and product categories can flag genuinely unusual situations whilst ignoring expected variations.
Business impact assessment evaluates potential consequences before generating alerts, suppressing notifications about issues with minimal customer or financial implications. A 30-minute delay affecting one low-value shipment warrants different treatment than similar delays impacting fifty high-value customers with premium service commitments.
Actionability requirements ensure every alert includes clear information about what actions should be taken, who should take them, and what resources are needed. Alerts describing problems without indicating potential solutions or responsible parties create confusion and delays rather than driving rapid resolution.
Scope and aggregation logic combine related issues into single coherent notifications rather than fragmenting problems across dozens of individual alerts. When a carrier experiences systematic delays affecting multiple shipments, one consolidated notification with affected order listings proves more valuable than individual alerts for each shipment.
How should you structure multi-tiered alerting systems?
Building escalation frameworks that match notification urgency to issue severity
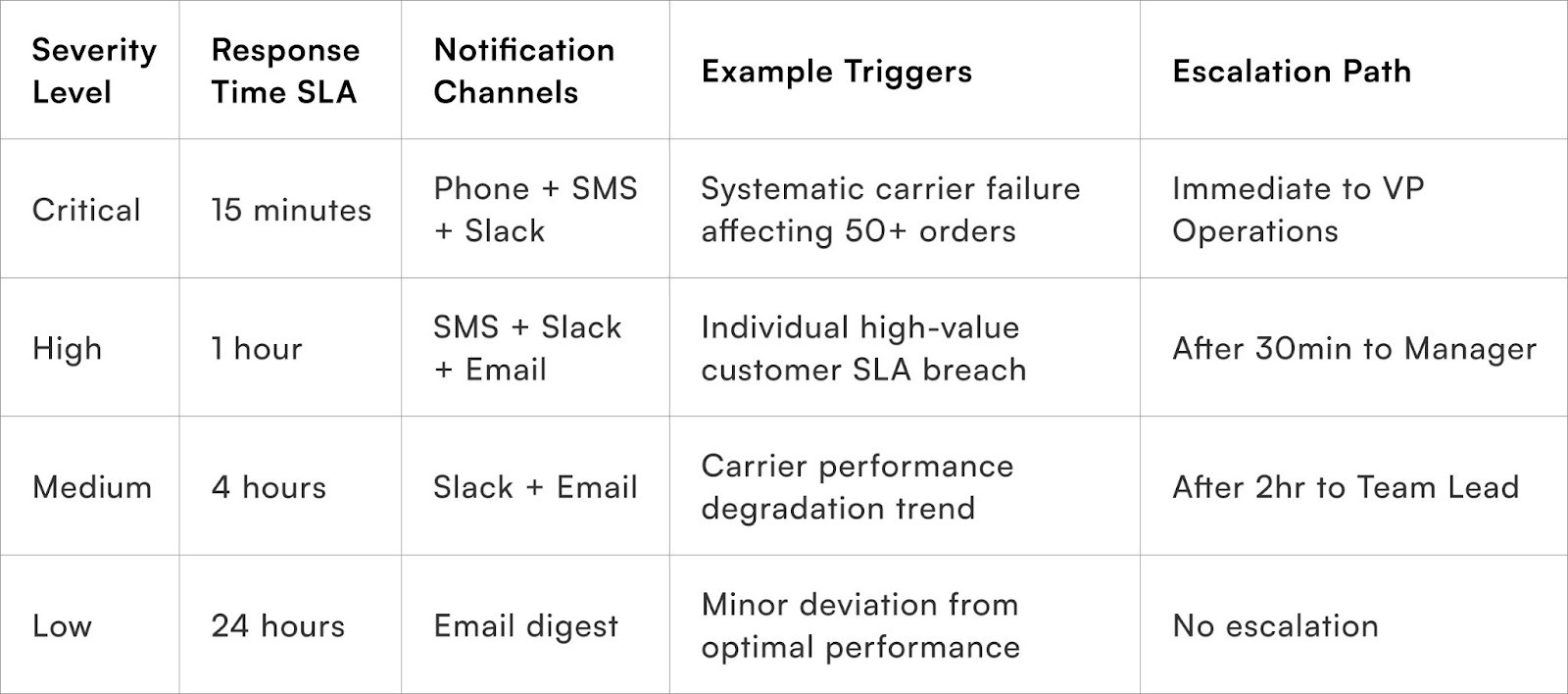
Multi-tiered alerting creates hierarchical notification systems where issue severity determines both alert recipients and communication channels used, ensuring critical problems reach decision-makers immediately whilst routine matters route through appropriate operational channels.
Severity classification establishes clear criteria distinguishing critical, high, medium, and low priority issues based on customer impact, financial exposure, and operational urgency. Critical alerts indicate widespread failures or high-value customer service failures requiring immediate executive attention, whilst low priority notifications document minor deviations for trend analysis without demanding immediate action.
Channel selection matches communication methods to urgency levels, reserving intrusive channels like phone calls and SMS for genuinely critical situations whilst routing routine notifications through less disruptive channels like email digests or dashboard updates. This discipline prevents channel fatigue where team members ignore or mute notification channels that cry wolf repeatedly.
Escalation timing defines how long issues can remain unaddressed at each severity level before automatically escalating to more senior personnel or broader distribution lists. Time-based escalation ensures critical issues cannot languish in individual queues when assigned personnel are unavailable or overloaded.
On-call rotation management distributes alert burden across teams to prevent individual burnout whilst ensuring 24/7 coverage for time-sensitive operations. Proper rotation schedules include clearly defined handoff procedures, escalation paths when on-call personnel cannot respond, and workload balancing to prevent alert fatigue accumulation.
Aggregation windows group related alerts occurring within defined timeframes into single notifications rather than bombarding recipients with separate messages for each occurrence. Time-windowed aggregation transforms fifty individual shipment delay alerts into one consolidated notification listing all affected orders, reducing cognitive load whilst maintaining complete visibility.
Contextual routing directs alerts to personnel with relevant expertise and authority to address specific issue types. Carrier performance problems route to logistics coordinators, payment failures reach finance teams, and customer communication issues escalate to support managers based on alert classification.
Feedback integration allows recipients to acknowledge alerts, indicate resolution progress, and provide outcome information that helps systems learn which notifications drove valuable action. This feedback loop enables continuous improvement of alert rules and severity classifications based on operational experience.
How SLA Breach Detection Works in Real Time
Real-time SLA breach detection continuously ingests data from multiple operational systems and applies logic to identify anomalies or risk patterns that suggest a future breach.
Here’s how it typically works in an e-commerce environment:
1. Event Stream Collection
Systems capture event signals such as order dispatch, scan updates, delivery attempts, support replies, carrier logs and customer confirmations.
2. Time-Window Analysis
Data is evaluated in real time against SLA windows — for example, how much time remains before a delivery is due — and compared with expected progress.
3. Predictive Scoring
Using rules or machine learning, systems assign a risk score to each order or ticket, indicating the likelihood of an SLA breach (e.g., low, medium, high).
4. Alert Triggers
When a risk score crosses defined thresholds, alerts are fired to operations, support or logistics teams through email, dashboards or messaging channels such as Slack/WhatsApp.
5. Actionable Recommendations
Some platforms provide suggestions — such as switching carriers, notifying customers proactively, reassigning fulfilment slots or escalating support tickets.
This real-time, signal-driven approach ensures SLA breaches are flagged before they materialise, enabling operational rescue actions rather than mere reporting.
Which metrics actually predict SLA breaches before they occur?
Identifying leading indicators that enable proactive intervention
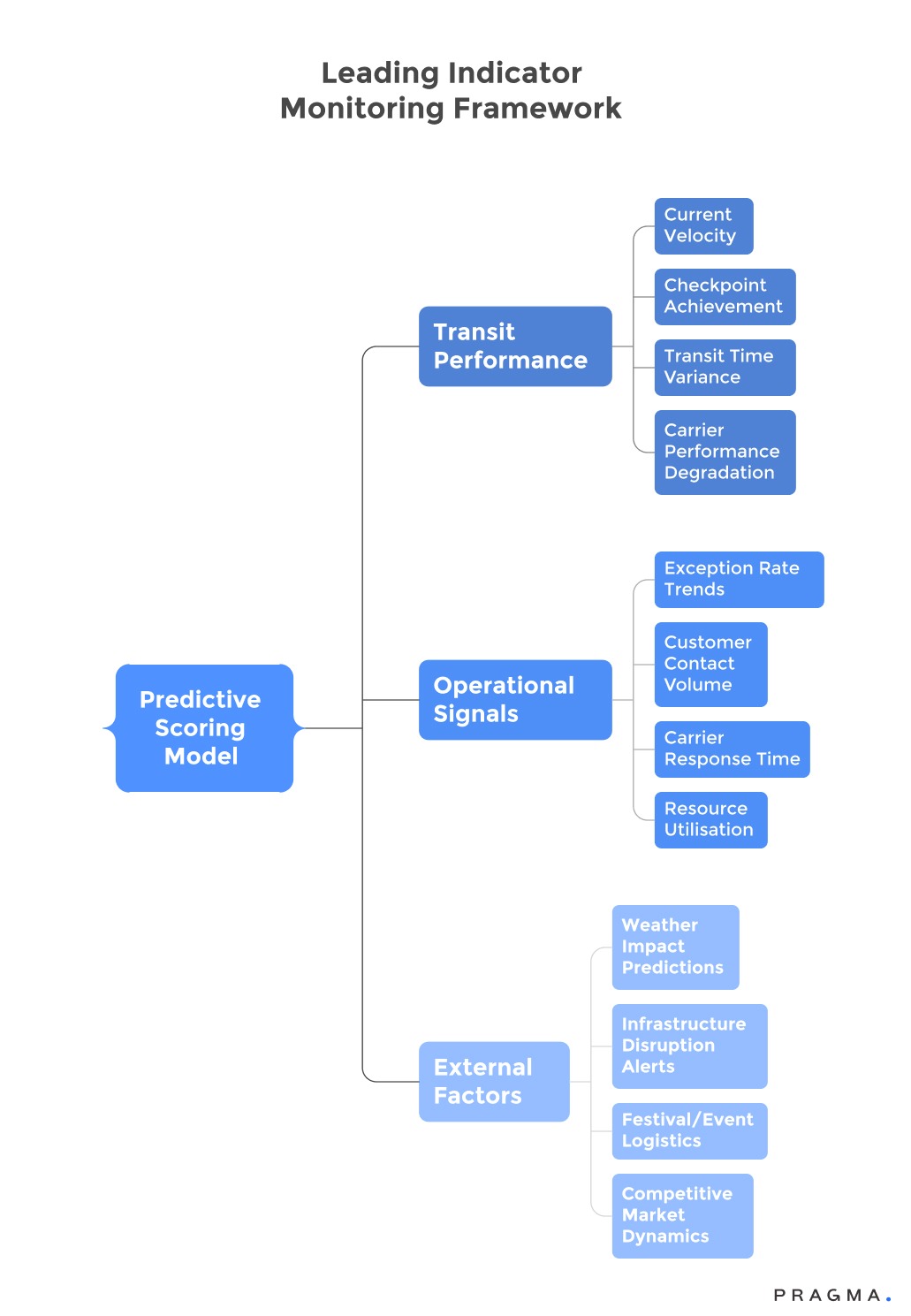
Predictive SLA management uses leading indicators to identify emerging issues before they become customer-impacting breaches. This allows for proactive intervention, preventing problems rather than just documenting failures.
Key indicators include:
- Carrier Transit Velocity Tracking: Monitors shipment speed against historical data. For instance, if a route segment typically taking six hours now takes eight, the likelihood of a breach increases, even if the final deadline hasn't passed.
- Checkpoint Achievement Rates: Tracks the percentage of shipments meeting milestones within target times. Declining rates, such as missing an "Out for Delivery by 10 AM" checkpoint, can predict final delivery delays hours in advance.
- Exception Rate Monitoring: Identifies increasing frequencies of delivery exceptions like customer unavailability or address issues, which historically correlate with delivery failures. A rise in exception rates within specific areas or carrier networks suggests systemic problems needing operational attention.
- Carrier Communication Responsiveness: Measures how quickly logistics partners acknowledge issues, provide updates, and take recovery actions. Degraded communication often precedes service quality decline, indicating overloaded carrier support systems.
- Weather and Infrastructure Alerts: Integrates external data to anticipate and proactively adjust deadlines based on conditions like monsoon warnings, festival traffic, or maintenance schedules.
- Customer Contact Pattern Analysis: Detects unusual support inquiry volumes or complaint types that signal brewing delivery problems. Spikes in "Where is my order?" inquiries often precede measurable delivery performance degradation.
- Resource Utilisation Metrics: Tracks carrier capacity, warehouse processing loads, and support team workloads to predict performance bottlenecks. Approaching capacity limits signal increased breach likelihood even if current performance is acceptable.
- Seasonal Performance Trends: Compares current performance against historical patterns for similar periods to identify unexpected deviations. For example, performance below typical festival season capabilities despite lower volumes may indicate carrier operational difficulties.
7 Key Signals That Indicate an Upcoming SLA Breach
To detect SLA breaches proactively, brands must monitor a combination of upstream signals that frequently precede actual violations:
1. Delayed or Missing Scans
When a parcel fails to register expected transit scans, this often correlates with delivery delays.
2. Carrier Performance Degradation
Drops in carrier SLA adherence over short time windows can signal broader systemic risk.
3. Weather and Transit Disruptions
External feeds, such as weather alerts or network issues, inform delivery timelines before they slip.
4. Address Verification Failures
Incomplete or unverified address data frequently predicts failed delivery attempts.
5. Customer Unavailability Patterns
Previous missed delivery attempts or lack of pre-delivery confirmations indicate higher breach risk.
6. High Support Case Volume in a Region
When support tickets spike for delivery issues in a geographical cluster, this can signal emerging SLA stress.
7. Payment Confirmation Delays (COD)
For Cash-on-Delivery orders, delayed payment confirmations often correlate with subsequent delivery or fulfilment hold-ups.
Tracking these signals — both internal and external — allows teams to surface probable SLA breaches far earlier than outcome-focused monitoring.
How can you reduce false positive rates without missing real issues?
Balancing detection sensitivity with operational efficiency
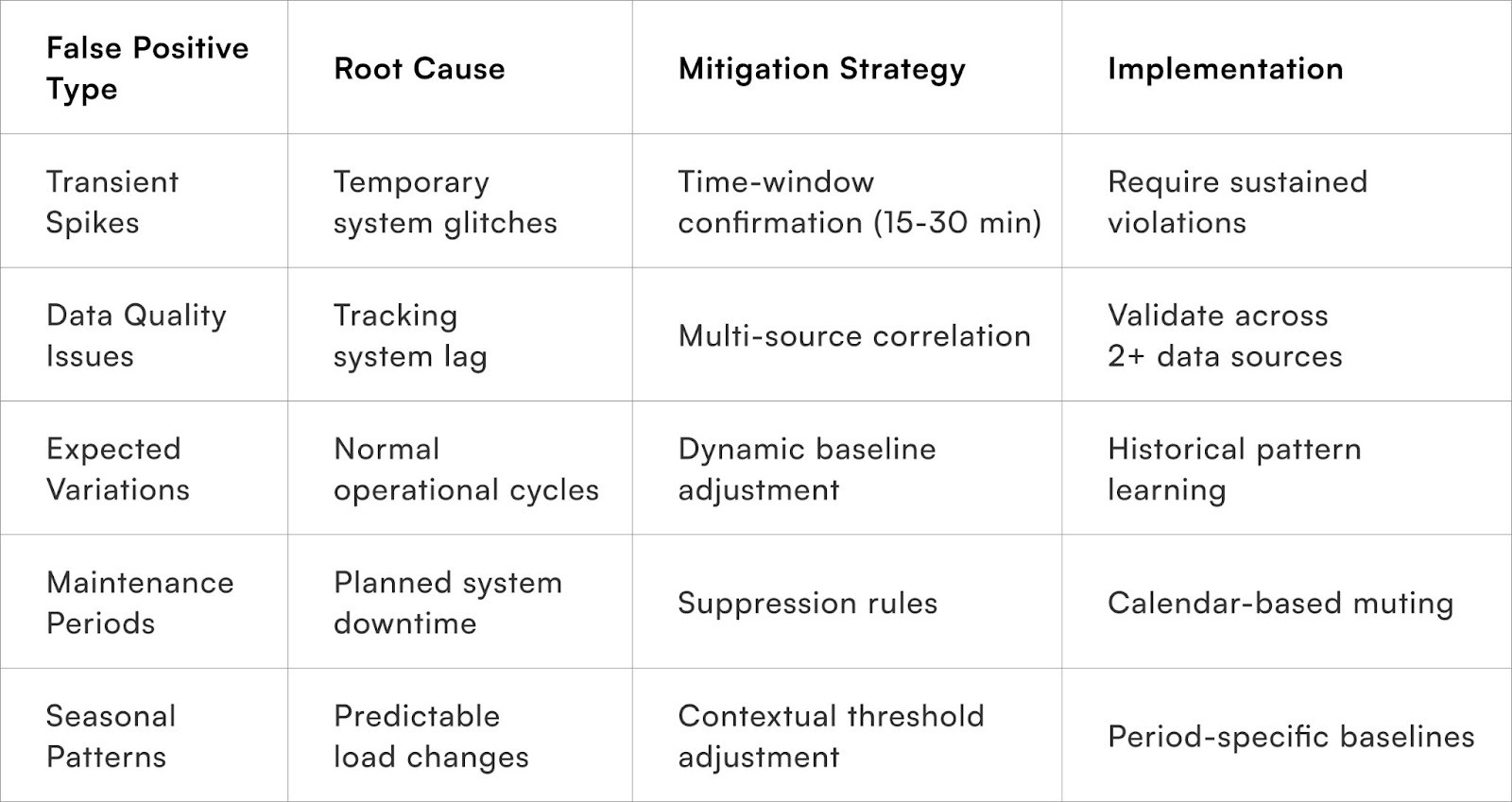
Effective alert systems are crucial, but an abundance of false positives can desensitise teams and obscure genuine issues. Reducing this noise while ensuring critical alerts are not suppressed requires a multi-faceted approach, incorporating intelligent design, statistical analysis, and continuous learning.
Core Techniques for False Positive Reduction:
- Intelligent Rule Design and Calibration:
- Baseline Calibration: Establish realistic performance expectations by analysing historical data. Instead of setting aspirational targets that frequently trigger alerts, understand natural variations (e.g., longer delivery times for certain postal codes, predictable weekend delays for specific carriers). This prevents treating expected fluctuations as anomalies.
- Confidence Thresholds: Require multiple confirming signals before generating an alert. A single, isolated data point or temporary fluctuation is less likely to be a genuine issue than a series of consistent deviations. For example, three consecutive shipment delays are more indicative of a systemic problem than a single delayed checkpoint.
- Data Analysis and Correlation:
- Correlation Engines: Examine relationships between different signals to differentiate genuine problems from measurement errors or transient issues. If GPS data shows normal progress, but a carrier API reports delays, the discrepancy points to a data quality problem rather than an actual service failure.
- Time-Window Analysis: Evaluate whether issues persist over meaningful periods rather than being momentary blips. Alerts should only be triggered if thresholds are consistently violated over defined intervals (e.g., 15-30 minutes), suppressing false positives from brief system hiccups while still catching sustained performance problems.
- Proactive Suppression and Machine Learning:
- Suppression Rules: Prevent alerts during known operational procedures that might appear as issues but are not service failures. This includes scheduled maintenance windows, data synchronisation periods, or other planned events (e.g., carrier system maintenance temporarily disrupting tracking updates should not trigger delivery failure alerts).
- Machine Learning Classification: Utilise historical alert outcomes to predict which current alerts are genuine issues requiring intervention versus noise that will self-resolve. Models trained on vast datasets of previous alerts can learn patterns to distinguish actionable situations from false alarms.
- Continuous Improvement and Adaptability:
- Feedback-Driven Tuning: Adjust alert rule sensitivity based on operational team responses. Tighten thresholds that generate excessive dismissed notifications and loosen rules where genuine issues were initially missed. This iterative refinement continuously improves alert quality.
- Seasonal and Contextual Adjustment: Automatically modify detection sensitivity based on business context. During predictable high-stress periods like festivals, the system can become more tolerant, while maintaining stricter thresholds during normal operations when breaches are more likely to indicate genuine problems.
By implementing these strategies, organisations can build more effective and reliable alert systems, ensuring that operational teams receive relevant and actionable information while minimising the distraction of false positives.
What role does automation play in breach response?
Leveraging intelligent systems to accelerate resolution without human bottlenecks
Automated breach response converts passive monitoring into proactive problem-solving by initiating corrective actions immediately upon issue detection. This reduces the mean time to resolution and allows operations teams to concentrate on complex issues that require human intervention.
Key automated response mechanisms include:
- Automatic Carrier Escalation:
When breaches are detected, predefined communication sequences are triggered. This notifies logistics partners of shipment delays and requests status updates without manual intervention. API integrations can automatically create priority tickets in carrier support systems, speeding up problem acknowledgment and resolution.
- Customer Proactive Communication:
Automated notifications are sent to affected customers before they independently notice problems. These communications acknowledge delays, explain the situation, and offer alternatives like delivery rescheduling or expedited replacement shipments. Proactive communication helps maintain customer trust even during service disruptions.
- Alternative Routing:
At-risk shipments are automatically rerouted to backup carriers or alternative delivery methods when primary plans indicate a high probability of breach. Intelligent systems can divert packages from delayed carrier networks to competitors with available capacity, preventing SLA violations through dynamic logistics network utilisation.
- Compensation Automation:
Predefined remediation policies, such as shipping refunds, loyalty points, or discount codes, are automatically applied to affected customers based on breach severity and customer segment. Automated compensation delivery avoids lengthy support interactions and maintains customer goodwill during service failures.
- Internal Workflow Automation:
This creates incident tickets, assigns tasks to appropriate team members, schedules follow-up actions, and tracks resolution progress without manual coordination. Automated workflows ensure that no details are missed during high-pressure situations when multiple issues demand attention.
- Documentation Generation:
Breach details, response actions taken, and resolution outcomes are automatically captured for post-incident analysis and carrier performance reporting. Comprehensive automated documentation supports SLA penalty claims against carriers and facilitates continuous improvement analysis.
- Capacity Reallocation:
Order routing, carrier selection, and service level offerings are dynamically adjusted based on real-time network capacity and performance data. When certain carriers or pincodes show elevated breach risk, systems automatically reduce order allocation until performance stabilises.
Tools for SLA Breach Detection & Alerts
To operationalise SLA breach detection, brands typically rely on a combination of:
Real-Time Event Streaming Platforms
Tools like Kafka, Pub/Sub or event hubs that capture operational events from OMS, logistics and support systems.
Automation & Rules Engines
Platforms that evaluate real-time data against conditional logic to assign breach risk — such as no-code workflow engines, CDPs with event logic, or specialised SLA engines.
Analytics & Prediction Layers
Machine learning or statistical forecasting setups that model expected versus actual timelines to score breach risk.
Alerting & Notification Channels
Integrated alerts via Slack, Microsoft Teams, email or WhatsApp/SMS to ensure operational teams take timely action.
Unified Dashboards & Operational Command Centres
Centralised dashboards that correlate fulfilment data with SLA health metrics across carriers, regions and products.
Integration with Support & CRM Systems
When SLA breach alerts flow into support and CRM platforms, customer communications can be triggered proactively — reducing inbound tickets and negative experience.
Selecting tools that combine real-time ingestion, predictive analytics and multi-channel alerts enables brands to shift from reactive breach reporting to proactive SLA assurance
Quick Wins for Intelligent SLA Monitoring Implementation (30 Days)
Build foundational intelligent monitoring capabilities through strategic infrastructure setup and rule refinement that immediately reduces alert fatigue whilst improving breach detection accuracy.
Week 1: Alert Audit and Baseline Establishment
Conduct comprehensive review of all current SLA alerts to identify which notifications drive action versus which are routinely ignored or dismissed. Analyse the last 30 days of alert history, categorising each alert by outcome—immediate action taken, delayed action, false positive dismissed, or completely ignored.
Document current alert volumes by severity level, notification channel, and issue type to establish baseline understanding of notification burden on operations teams. Calculate metrics like alerts per day, acknowledgment rates, time-to-acknowledge, and false positive percentages.
Interview operations team members about alert fatigue experiences, asking which notifications they find valuable versus distracting. Gather specific examples of missed critical alerts due to noise, and situations where alert timing or content proved unhelpful.
Week 2: Rule Refinement and Prioritisation
Eliminate or consolidate redundant alerts generating duplicate notifications about identical issues. Configure aggregation windows that group related alerts occurring within 15-30 minute periods into single consolidated notifications.
Implement severity-based thresholds that reserve critical alerts for situations genuinely requiring immediate attention. Reclassify routine monitoring alerts as medium or low priority, routing them to dashboard views or email digests rather than intrusive notification channels.
Establish contextual baselines that adjust alert sensitivity based on time, day, season, and known operational patterns. Configure rules to expect slower performance during peak hours, festivals, or adverse weather rather than treating predictable variations as anomalies.
Week 3: Channel Optimisation and Escalation
Redesign notification routing to match communication channels with alert severity appropriately. Reserve phone calls and SMS for critical breaches only, route high priority alerts through Slack or team chat platforms, and send medium priority notifications via email.
Configure escalation timers that automatically elevate unacknowledged critical alerts to broader distribution lists or senior personnel after predefined intervals. Implement on-call rotation schedules that distribute alert burden across teams whilst ensuring 24/7 coverage.
Integrate feedback mechanisms allowing operations teams to acknowledge alerts, indicate resolution actions, and mark false positives directly from notification interfaces. Use feedback data to begin tuning rule sensitivity and classification accuracy.
Week 4: Automation and Continuous Improvement
Deploy automated customer communication for detected breaches that send proactive delay notifications, apology messages, and resolution updates without manual intervention. Configure message templates that populate automatically with shipment-specific details and estimated resolution timelines.
Implement automated carrier escalation that creates priority support tickets with logistics partners immediately upon breach detection. Configure API integrations that transmit shipment details, delay information, and requested actions directly to carrier systems.
Establish weekly alert quality review processes that examine false positive rates, missed breach incidents, and team feedback to continuously refine detection rules. Create improvement roadmaps prioritising rule adjustments with highest impact on alert quality and operational efficiency.
Expected Results After 30-Day Implementation:
- 40-60% reduction in overall alert volume through consolidation and filtering
- 70-80% decrease in false positive alerts through refined thresholds
- 50-60% faster breach acknowledgment through better prioritisation
- 30-40% reduction in customer complaints through proactive communication
- Improved team morale and reduced operational stress from alert fatigue
To Wrap It Up
Intelligent SLA breach detection represents the difference between reactive firefighting and proactive operations management. Organisations that master this discipline create sustainable competitive advantages through superior delivery reliability without burning out operations teams through constant crisis response.
Start with an alert audit this week—document every current notification, categorise by usefulness, and eliminate the bottom 30% creating pure noise. This single action immediately reduces alert fatigue whilst focusing attention on signals that matter.
Remember that monitoring systems require continuous refinement rather than one-time configuration. Customer expectations evolve, carrier networks change, and operational contexts shift, demanding ongoing attention to keep detection rules aligned with current realities.
The most successful brands view SLA monitoring as strategic capability rather than technical infrastructure. Investing in intelligent detection pays dividends through improved customer satisfaction, reduced operational stress, and protected profit margins that would otherwise erode through undetected service failures.
For D2C brands seeking sophisticated SLA monitoring that balances sensitivity with operational sustainability,Pragma's intelligent breach detection platform provides AI-driven rule engines, contextual alerting, and automated response workflows that help brands achieve 95%+ breach detection accuracy whilst reducing alert fatigue by 60-70% through smart filtering and escalation management.
.gif)
FAQs (Frequently Asked Questions On SLA Breach Detection: Real-Time Rules and Alert Fatigue Reduction)
How many alerts per day indicate an alert fatigue problem?
When operations teams receive more than 50-75 alerts daily, alert fatigue typically emerges as teams begin ignoring or dismissing notifications without proper evaluation. Critical alert frequency should remain below 3-5 per day to maintain appropriate urgency perception.
Should SLA monitoring focus on carrier performance or internal operations?
Comprehensive monitoring requires both perspectives—carrier performance tracking identifies external service failures, whilst internal operations monitoring reveals process bottlenecks and systematic inefficiencies within your control. Balanced monitoring prevents blind spots whilst enabling accountability discussions with logistics partners.
What's the right balance between automated responses and human oversight?
Automate routine responses like customer notifications and carrier escalations for common scenarios, but require human judgment for complex situations involving high-value customers, unusual circumstances, or decisions with significant financial implications. Aim for 70-80% automation of routine scenarios whilst maintaining human oversight of edge cases.
How do you prevent alert systems from becoming desensitised over time?
Implement continuous feedback loops where operations teams regularly rate alert usefulness, combined with quarterly comprehensive reviews that analyse which alerts drove action versus noise. Dynamic threshold adjustment based on seasonal patterns and ongoing rule refinement prevents stagnation and maintains relevance.
Should different customer segments have different breach detection thresholds?
Absolutely—premium customers or high lifetime value segments warrant more sensitive monitoring and faster escalation than occasional shoppers. Segment-specific thresholds ensure operational resources concentrate on protecting relationships with greatest business value whilst maintaining baseline service for all customers.
Why do brands need real-time SLA breach detection?
Without it, delays show up only via customer complaints; real-time detection lets ops teams react early with carrier escalations, re-routes, or updated ETAs.
How do you avoid alert fatigue with breach alerts?
Group alerts by lane or carrier, set thresholds for only high‑impact breaches, and use risk-based rules so ops sees the few shipments that really need intervention.
How can breach detection improve customer experience?
If you know a shipment will be late, you can inform customers proactively, offer options, and preserve trust instead of surprising them at the last minute.
Does SLA breach detection also help in carrier negotiations?
Yes, it produces hard data on which carriers or lanes miss SLAs most often, which strengthens discussions on penalties, credits, or reallocation of volume.
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo
%20in%20E-commerce%20Streamlining%20Your%20Return%20Process.png)

.png)