

If Indian addresses were written once and used forever, last-mile delivery would be simple. In reality, the same location can appear in English, Hindi, Tamil, or a mix of phonetic spellings—sometimes all within the same order history. What looks like a minor data issue quickly becomes an operational one, triggering failed attempts, repeated NDRs, and unnecessary customer calls.
Transliteration and address normalisation across Indian scripts: tactics and tools explores how D2C operations teams can bring consistency to address data without forcing customers into rigid formats. The challenge is not translating text perfectly, but making addresses usable for routing, validation, and delivery execution.
By treating transliteration and normalisation as part of the order pipeline rather than a downstream clean-up task, brands can reduce ambiguity before parcels ever leave the warehouse. The payoff is fewer address-related failures, better carrier handoffs, and more predictable delivery outcomes across regions and scripts—without compromising on customer experience.
Why do Indian scripts and spellings break standard address systems?
Structural language diversity meets rigid logistics workflows
Multiple scripts, phonetics, and informal locality names
India’s address ecosystem is inherently multilingual. Customers often write addresses in the script they are most comfortable with, mix English with regional languages, or rely on phonetic spellings that make sense locally but not to standard parsers. Informal locality names, landmarks, and shortened references further increase ambiguity.
Common address variations include:

- Native scripts (Hindi, Tamil, Telugu, Bengali, etc.)
- Phonetic English spellings of regional names
- Mixed-script entries within a single line
- Landmark-heavy descriptions with minimal structure
Why “free-text” addresses are operationally fragile
Without structure, even small spelling differences can derail validation and routing.
How do script mismatches affect last-mile performance?
Where data inconsistency turns into delivery failure
Breakdown points between checkout and doorstep
Script mismatches rarely cause a single obvious failure. Instead, they introduce friction at multiple stages — address validation, hub sorting, rider navigation, and customer contact. Each handoff adds interpretation overhead, increasing the chance of delay or misdelivery.
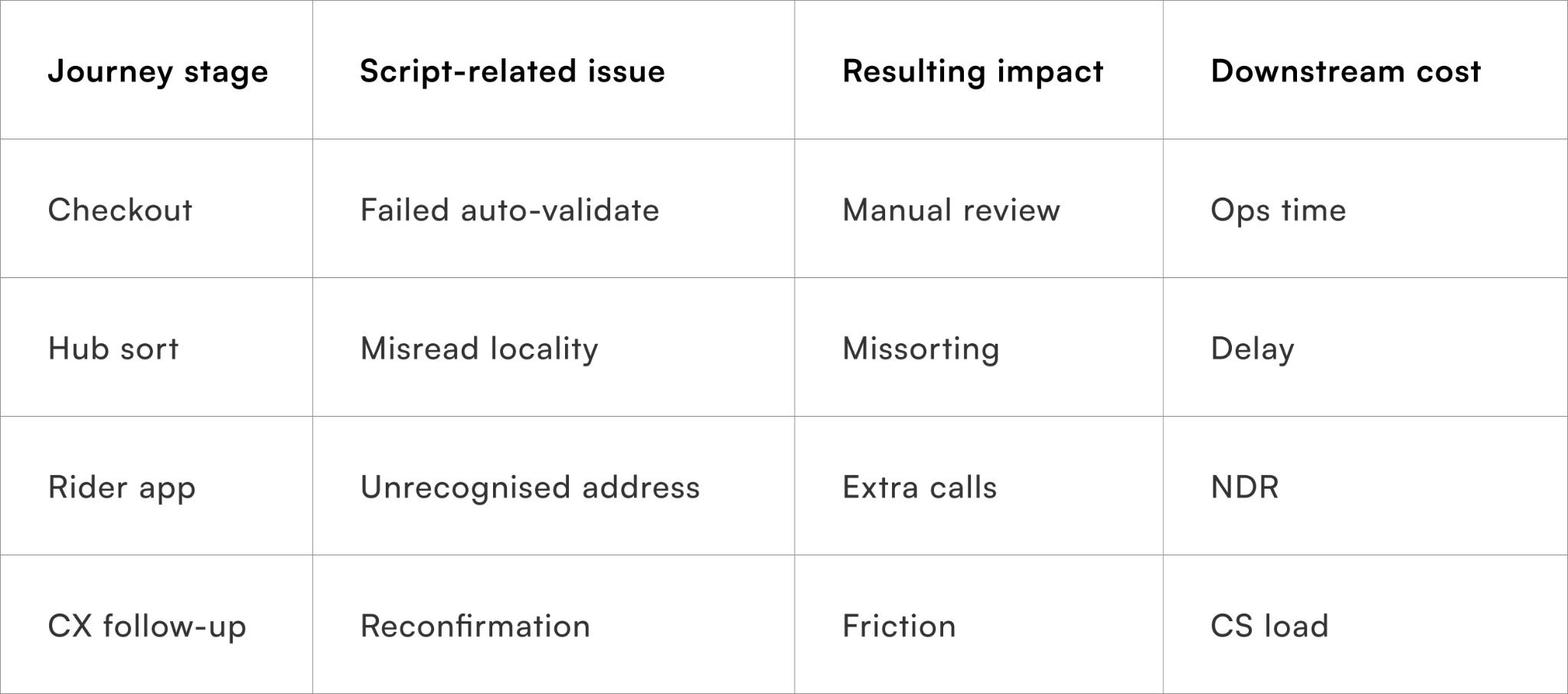
Why last-mile teams feel this first
Riders and CX absorb ambiguity that upstream systems failed to resolve.
What address elements matter most for normalisation?
Prioritising what actually improves deliverability
Separating critical fields from “nice-to-have” detail
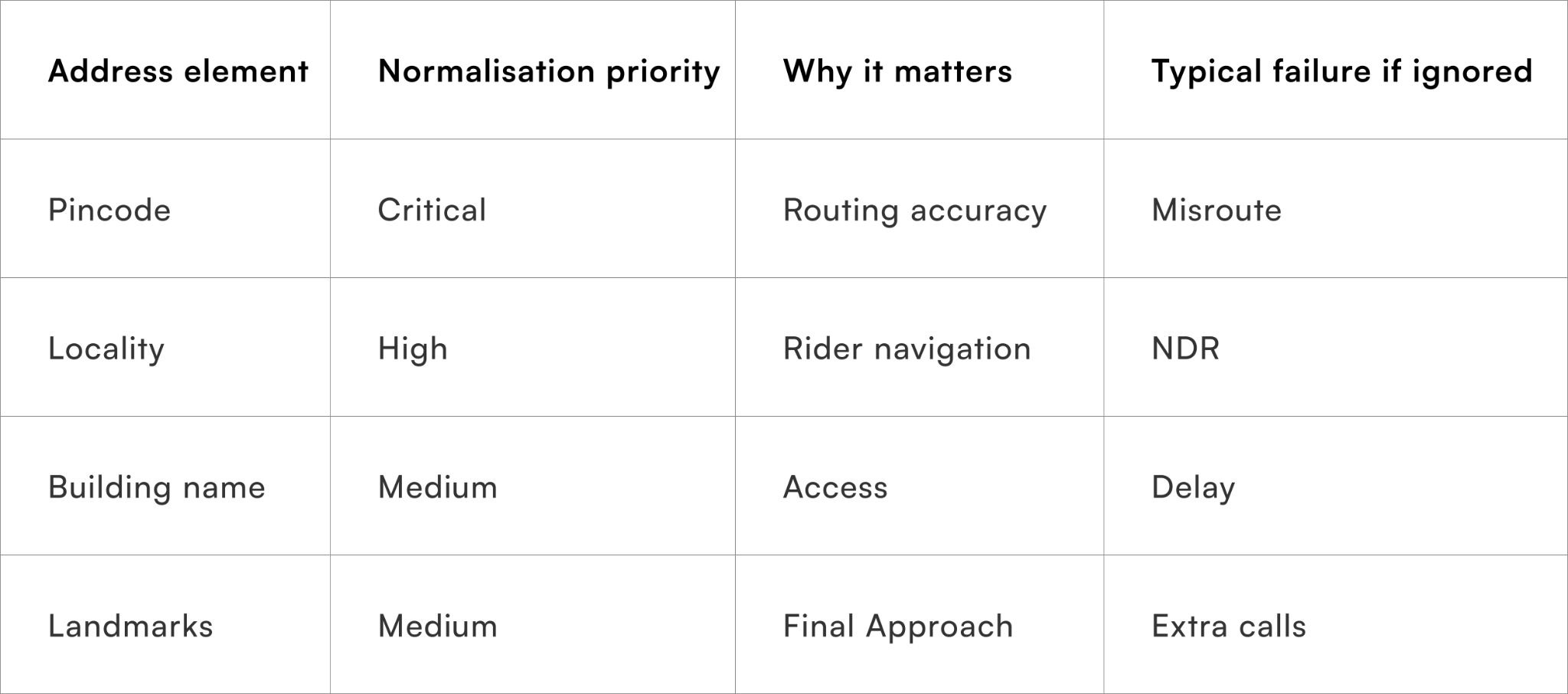
Not all address components contribute equally to delivery success. Normalisation efforts should focus on elements that directly impact routing and rider navigation, rather than chasing perfect textual accuracy.
High-impact elements include:
- Pincode and sub-pincode accuracy
- Locality and neighbourhood naming
- Building or society identifiers
- Landmark consistency
Why over-normalising can backfire
Excessive standardisation can remove cues riders actually rely on.
Why manual correction does not scale?
The limits of human interpretation
Hidden cost of CX and ops intervention
Many teams rely on CX or ops staff to “fix” addresses post-order. While this works at low volume, it quickly becomes a bottleneck during sales or seasonal peaks. Manual correction is slow, inconsistent, and difficult to audit.

Why automation must respect linguistic context
Blind automation without script awareness creates new errors instead of removing them.
How can transliteration be applied without losing address intent?
Making text machine-readable while staying rider-friendly
Using reversible transliteration instead of hard replacement
Effective transliteration converts native scripts into a common working script (usually English) without discarding the original input. This allows systems to standardise processing while still retaining the customer’s original wording for reference, CX review, or rider context.
Best-practice transliteration pipelines:
- Store original address text alongside transliterated output
- Use language detection before applying conversion rules
- Avoid forced corrections when confidence is low
- Expose both versions to downstream systems where needed

Why reversibility matters in dispute resolution
Original text often carries cues lost in translation.
How do you handle ambiguous or incomplete addresses in real time?
Not every bad address should be blocked — but none should go unchecked
A significant portion of delivery failures doesn’t come from completely wrong addresses, but from partially correct, ambiguous, or incomplete ones. Missing house numbers, vague landmarks, or mismatched locality–pincode combinations often slip through checkout because they are still “technically valid” as free text.
Blocking these orders outright isn’t practical. It increases checkout friction and leads to drop-offs, especially in regions where informal addressing is common. But letting them pass untouched simply shifts the problem downstream.
The more effective approach is to introduce real-time validation layers that guide rather than restrict.
Instead of hard errors, systems can:
- Flag inconsistencies (e.g. locality not matching pincode)
- Suggest likely corrections based on historical data
- Prompt users for confirmation only when confidence is low
For example, if a user enters a known locality with a mismatched pincode, the system can surface a subtle prompt: “Did you mean [correct pincode]?” — without forcing a rewrite.
Where confidence is too low, these cases can be routed into a soft review layer post-order. This ensures that high-risk addresses are checked without disrupting the checkout experience for the majority of users.
Over time, combining real-time nudges with backend review creates a balance:
addresses become more reliable without becoming rigid.
How can delivery teams use rider and delivery feedback to improve address quality?
The most accurate address data often comes from the last mile itself
No matter how advanced the transliteration or normalisation system is, the ground truth of an address is validated at delivery. Riders constantly interpret, correct, and navigate ambiguous addresses — but this intelligence rarely feeds back into the system.
That’s a missed opportunity.
Every successful or failed delivery carries signals:
- Which landmarks actually helped locate the address
- Which locality names were misleading or outdated
- Which pincodes repeatedly caused confusion
- Which addresses required customer calls to resolve
Capturing even a fraction of this feedback can significantly improve future deliveries.
In practice, this doesn’t require heavy tooling. Simple mechanisms can make a difference:
- Allowing riders to confirm or adjust locality names post-delivery
- Logging when a delivery required a customer call for clarification
- Tagging repeated NDR reasons linked to specific address patterns
This data can then be fed back into:
- Locality synonym lists
- Address validation rules
- Confidence scoring systems
For example, if multiple riders consistently correct a locality spelling in a specific pincode, that variation can be automatically recognised in future orders instead of flagged as an error.
Over time, this creates a system that doesn’t just process addresses — it learns from actual delivery outcomes.
What role does checkout UX play in improving address quality?
Better inputs reduce the need for downstream correction
Address quality is often treated as a backend problem, but a large part of it is shaped at the point of entry — the checkout itself.
Small UX decisions can have a disproportionate impact on how structured or ambiguous an address becomes.
For instance, completely unstructured address fields give users flexibility, but they also encourage inconsistent formats. On the other hand, overly rigid forms can frustrate users who rely on landmarks or non-standard formats.
The balance lies in guided flexibility.
Effective checkout designs typically:
- Break address into logical fields (house, street, locality, landmark) without forcing strict formats
- Provide autofill suggestions for cities and pincodes
- Retain landmark fields instead of eliminating them
- Support multiple scripts without forcing transliteration at input
Microcopy also plays a role. A simple hint like “Add a nearby landmark for faster delivery” often improves address clarity more than strict validation rules.
Another important layer is persistence. Returning customers should not have to re-enter or re-correct addresses repeatedly. Storing cleaned and validated versions over time gradually improves overall data quality.
When checkout UX is designed with delivery in mind, the system starts with better inputs — reducing the need for heavy correction later.
How do you maintain consistency across systems handling address data?
Clean data at one stage is useless if it breaks at the next
One of the less visible challenges in address normalisation is maintaining consistency across systems. An address that is cleaned and structured at ingestion can still fail if downstream systems interpret it differently.
Typical fragmentation points include:
- Warehouse management systems using different field formats
- Courier APIs requiring specific address structures
- CRM tools displaying raw versus processed data
- Support teams referencing outdated address versions
Without alignment, teams end up working with multiple versions of the same address, leading to confusion and inconsistent actions.
The solution is not just better processing, but better propagation.
A consistent approach ensures that:
- The same normalised address is used across all systems
- Original and processed versions are both accessible where needed
- Updates (manual or automated) are reflected everywhere in real time
This becomes especially important in exception handling. If support teams see a different version of the address than what was sent to the courier, resolution slows down immediately.
Maintaining consistency doesn’t require a complete system overhaul, but it does require treating address data as a shared operational asset, not a field that each system manages independently.
How does normalisation fit into the order flow?
Fixing addresses early without breaking UX
Normalising at ingestion, not after failure
The most effective place to normalise addresses is immediately after order capture, before routing and carrier assignment. This ensures that all downstream systems work from a consistent representation.
A typical flow:
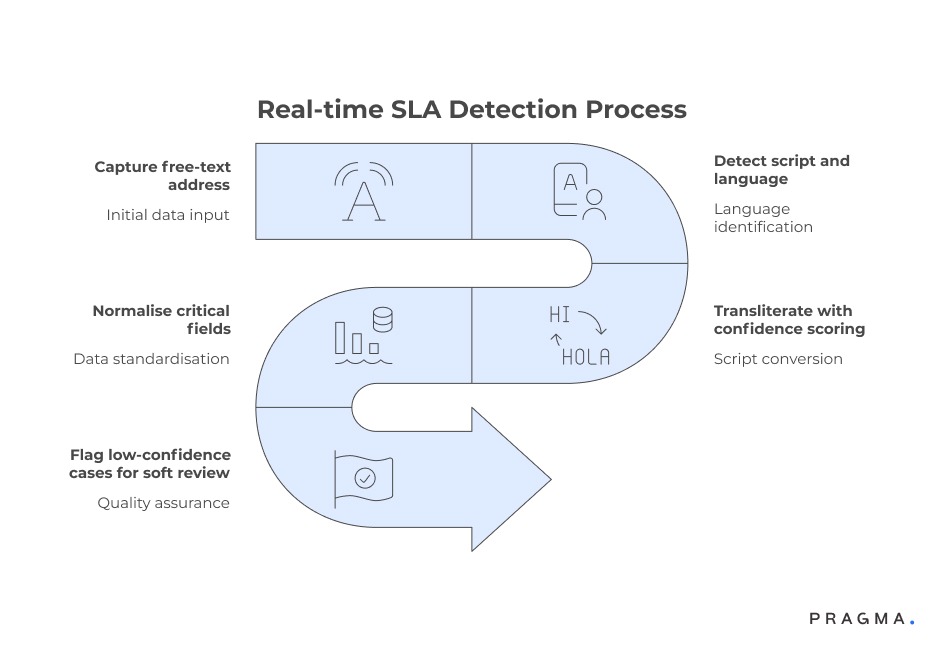
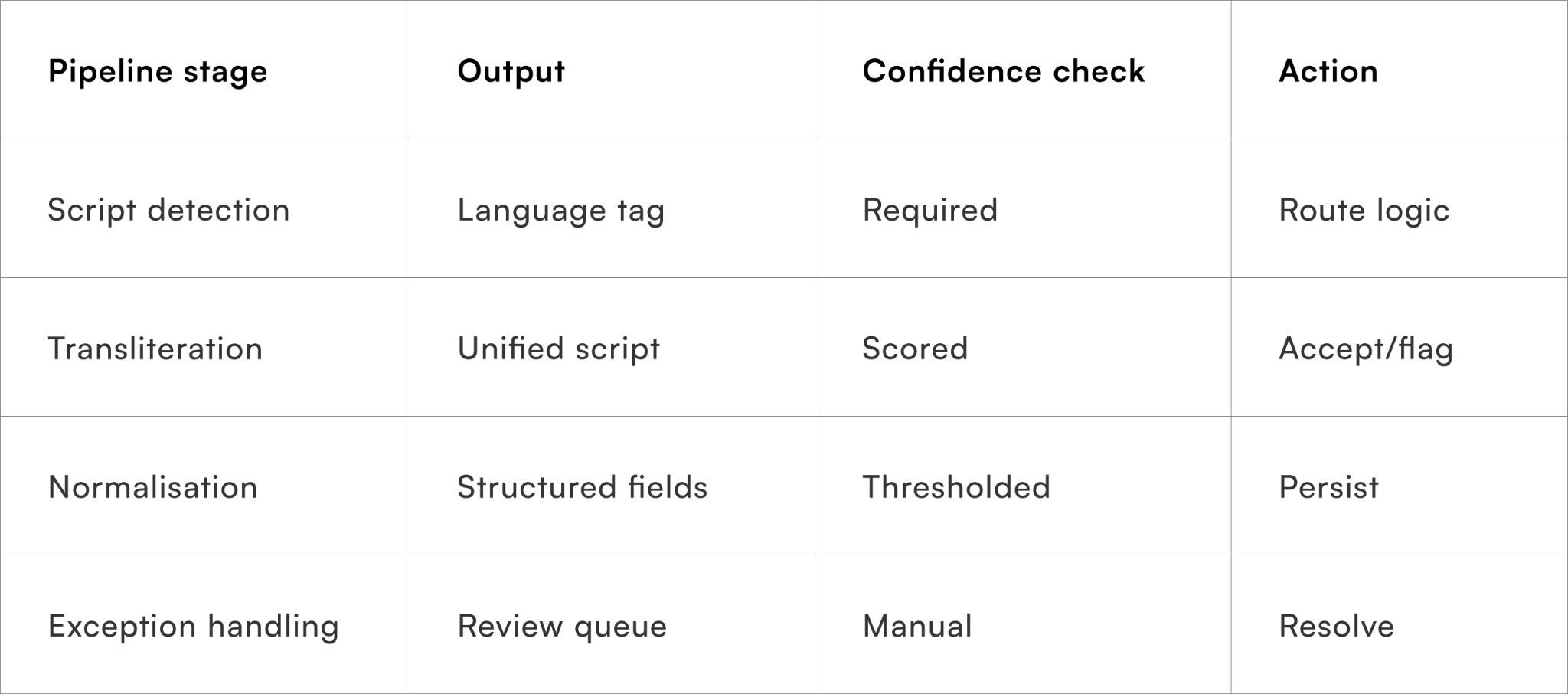
- Capture free-text address
- Detect script and language
- Transliterate with confidence scoring
- Normalise critical fields
- Flag low-confidence cases for soft review
Why early intervention reduces CX load
Fixing ambiguity pre-dispatch avoids downstream firefighting.
What tools actually work for Indian-script transliteration and normalisation?
Choosing practical tooling over theoretical language coverage
Indic language transliteration engines
These tools handle conversion from native scripts (Hindi, Tamil, Telugu, Bengali, etc.) into a working script such as English. The key requirement is robust phonetic handling, not perfect linguistic accuracy.
Operational selection criteria:
- Coverage across major Indian scripts
- Ability to return confidence scores
- Support for mixed-script inputs
- Low-latency performance for checkout flows
Examples of commonly used tool types:
- Open-source Indic transliteration libraries
- Cloud-based language APIs with Indian language support
These engines work best when paired with downstream validation rather than used in isolation.
Address parsing and entity extraction tools
Once transliterated, addresses must be broken into usable fields such as locality, landmark, street, and building name. Generic global parsers often fail on Indian formats, where landmarks and informal locality names dominate.
What to look for:
- Support for landmark-heavy address structures
- Tolerance for missing or reordered fields
- Custom entity rules for Indian address patterns

Reference datasets for locality and pincode validation
Transliteration alone does not guarantee correctness. Reference datasets ground addresses in operational reality by validating whether localities, pincodes, and administrative units logically belong together.
High-value datasets include:
- India Post pincode master data
- City and locality synonym lists
- Historical delivery-success mappings by pincode
These datasets are especially useful for:
- Catching mismatched locality–pincode pairs
- Resolving alternate spellings
- Powering confidence-based acceptance rules
Carrier-specific address validators and adapters
Each carrier applies its own address formatting and validation rules. Normalised addresses must still be adapted to carrier expectations to avoid rejections or silent failures.Ignoring this layer often results in “clean” internal data that still fails at handoff.
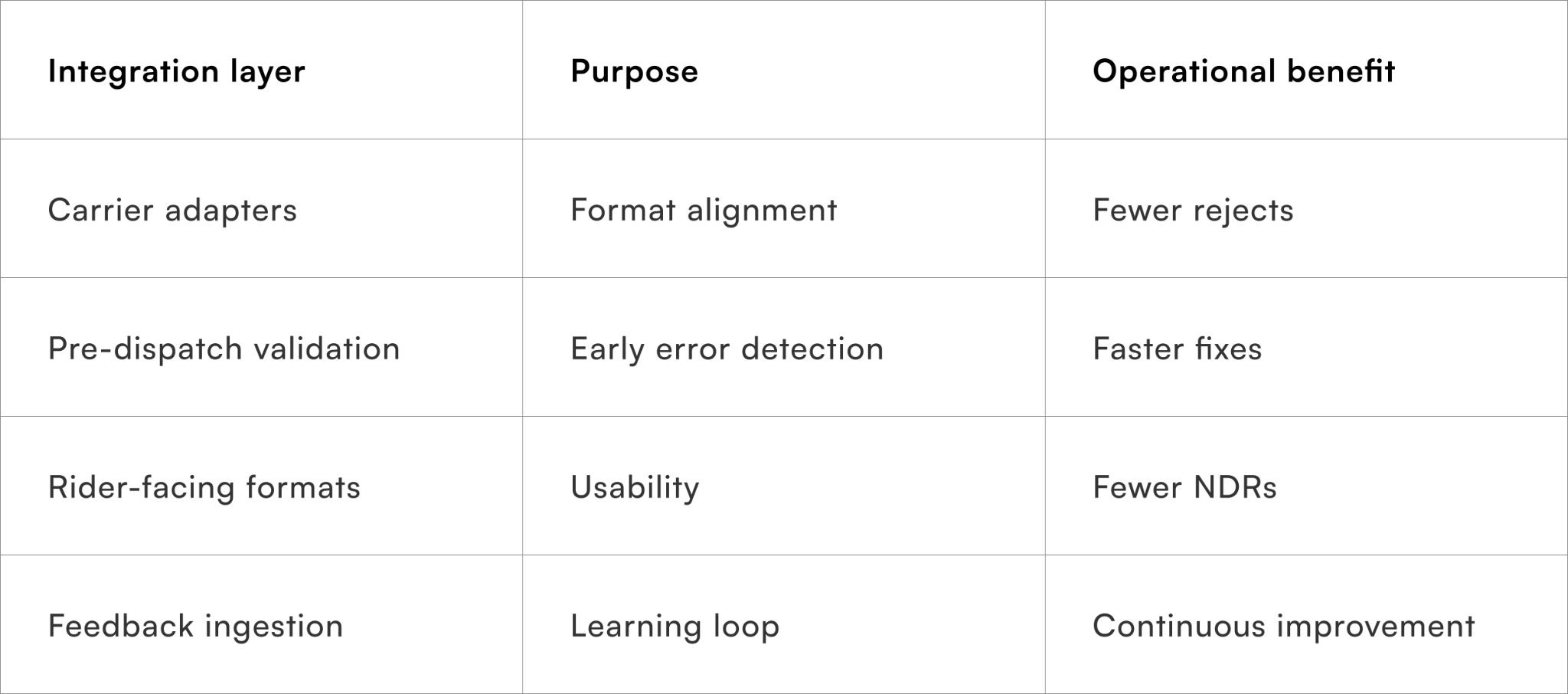
Why no single tool is enough
The most effective setups combine:
- Transliteration engines for script handling
- Parsers for structure
- Reference data for validation
- Carrier adapters for execution
Treating tools as modular layers — rather than searching for a silver bullet — keeps the system adaptable as languages, regions, and partners evolve.
Quick Wins
Reducing address-related failures without overhauling checkout
Week 1: Audit address-related NDRs
Review the last 60–90 days of NDR data and tag cases caused by address ambiguity, script issues, or locality confusion. Shortlist the top 5–7 pincodes or cities where these failures cluster.
By the end of the week, teams typically uncover repeat patterns masked as “customer unavailable” or “address not found”.
Week 2: Introduce script detection and soft transliteration
Add lightweight script detection post-checkout and generate transliterated versions of addresses in parallel with the original text. Do not block orders or force correction yet.
This step alone improves internal readability for ops and CX teams.
Week 3: Normalise high-impact fields only
Focus on pincode, locality, and building name normalisation using reference datasets. Apply confidence thresholds and route low-confidence cases to a review queue instead of auto-correcting.
Most brands see a reduction in address clarification calls within days.
Week 4: Close the delivery feedback loop
Compare delivery outcomes for normalised versus non-normalised addresses. Use success signals to tune confidence thresholds and expand coverage gradually.
At 30 days, address handling becomes proactive rather than reactive.
To Wrap It Up
Transliteration and address normalisation are not language problems; they are delivery reliability problems. Treating them as part of the order pipeline reduces ambiguity before it reaches riders, hubs, or CX teams.
This week, audit address-related NDRs and introduce script detection with reversible transliteration.
Over time, confidence-based automation and delivery feedback help standardise addresses without erasing local context or customer intent.
For D2C brands seeking reliable last-mile execution across languages and regions, Pragma’s orchestration platform enables script-aware address processing, carrier-aligned validation, and outcome-driven optimisation that reduce delivery failures and CX load.
.gif)
FAQs (Frequently Asked Questions On Transliteration and address normalisation across Indian scripts: tactics and tools)
1. How do I fix delivery issues caused by different Indian language spellings in addresses?
Inconsistent spellings across Hindi, Tamil, Telugu, or English can confuse routing systems. Using transliteration and normalisation tools helps standardise addresses while keeping the original intact for reference.
2. Why does my address work sometimes but fail delivery other times?
Even small variations in spelling or script can break validation or routing. Systems that normalise locality, pincode, and landmarks early in the order flow reduce these inconsistencies.
3. Can I use regional language addresses without affecting delivery success?
Yes, but they need to be transliterated into a common working format. Script-aware systems ensure addresses remain usable for logistics without forcing users to change input language.
4. What is the best way to handle mixed-language addresses in India?
Mixed-script addresses should be processed using language detection and reversible transliteration. This keeps them readable for both machines and delivery teams.
5. How do ecommerce brands reduce address-related NDRs in India?
Brands reduce NDRs by validating and normalising addresses at checkout or immediately after order capture. Platforms like Pragma help automate this across scripts and carriers.
6. Should I block orders with incomplete or unclear addresses?
Not always. Instead of blocking, use real-time prompts and confidence-based validation to guide users and flag risky addresses for review.
7. What address fields matter most for successful delivery in India?
Pincode, locality, building name, and consistent landmarks have the highest impact. Normalising these fields improves routing accuracy significantly.
8. Why doesn’t manual address correction scale for growing D2C brands?
Manual fixes are slow, inconsistent, and hard to audit at scale. Automated, script-aware normalisation reduces dependency on CX and ops teams.
9. How can delivery feedback improve address accuracy over time?
Rider inputs and delivery outcomes reveal which address formats actually work. Feeding this data back into validation systems helps continuously improve accuracy.
10. What tools work best for transliteration and address normalisation in India?
A combination works best—transliteration engines, address parsers, and pincode datasets. Solutions like Pragma unify these layers to ensure consistent, carrier-ready address data.
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo.png)


.png)