

Most support teams don’t struggle with isolated delays — they struggle with patterns. A missed response here, an escalated ticket there, a backlog spike during peak hours. Over time, these incidents stop looking random. They begin repeating. And when SLA violations repeat, they stop being operational noise and start becoming structural failure.
This is where root cause analysis for SLA violations becomes non-negotiable. Treating every breach as a one-off incident masks deeper inefficiencies in routing logic, staffing models, carrier dependencies, or workflow design. Without a disciplined approach, teams firefight symptoms while systemic friction compounds quietly.
In Root-cause analysis playbook for repeat SLA violations, we examine how to move beyond surface-level fixes and implement structured RCA frameworks that prevent recurring SLA failures — using practical, measurable approaches suited for high-volume D2C support environments.
Why do SLA violations keep repeating despite corrective action?
Surface fixes rarely address systemic friction
Most teams respond to an SLA breach with urgency. A supervisor steps in, tickets are reassigned, apologies are issued. The immediate issue closes. Yet, within days or weeks, the same pattern resurfaces.
This happens because corrective action is often reactive, not structural. Teams focus on “who missed it” instead of “why the system allowed it”.
Common recurring drivers include:
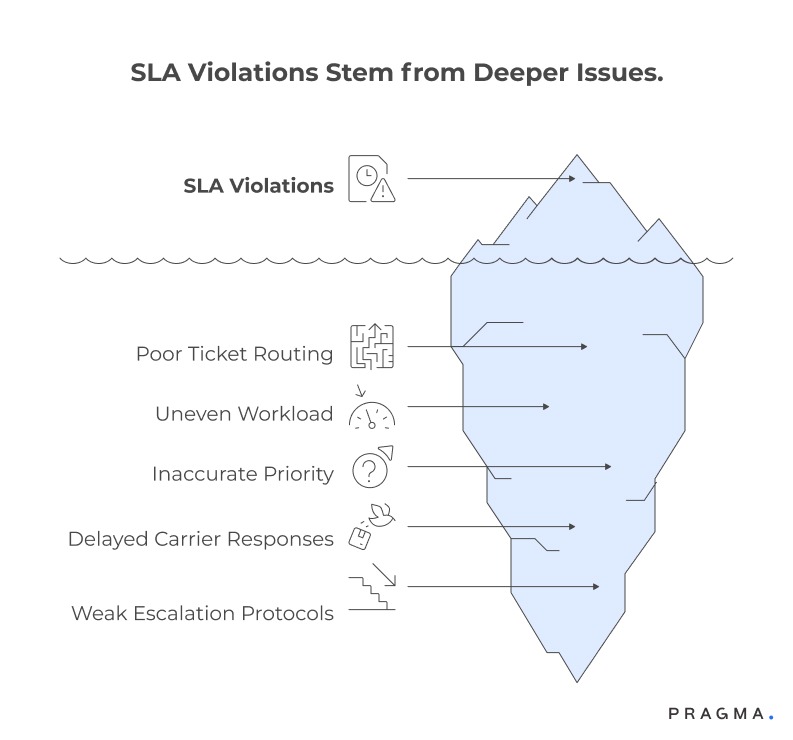
- Poor ticket routing logic
- Uneven workload distribution
- Inaccurate priority tagging
- Delayed carrier responses
- Weak escalation protocols
Without disciplined repeat SLA violation analysis, breaches become cyclical. The cost compounds — customer dissatisfaction rises, refund rates increase, and operational stress escalates.
Repeat violations are rarely caused by individual failure. They signal process design gaps.
What is root cause analysis for SLA violations and how does it differ from incident review?
Structured diagnosis replaces blame-driven retrospectives
Root cause analysis for SLA violations is a structured method to identify the underlying system flaw that allows breaches to occur repeatedly. It differs from a standard post-incident review in one critical way: it focuses on structural correction, not event documentation.
An incident review asks:
- What happened?
- Who handled it?
- Was the response delayed?
RCA asks:
- Why did the workflow allow delay?
- What upstream trigger failed?
- Which metric signalled risk earlier?
This distinction is what separates temporary improvement from sustained performance.
Consider the difference:
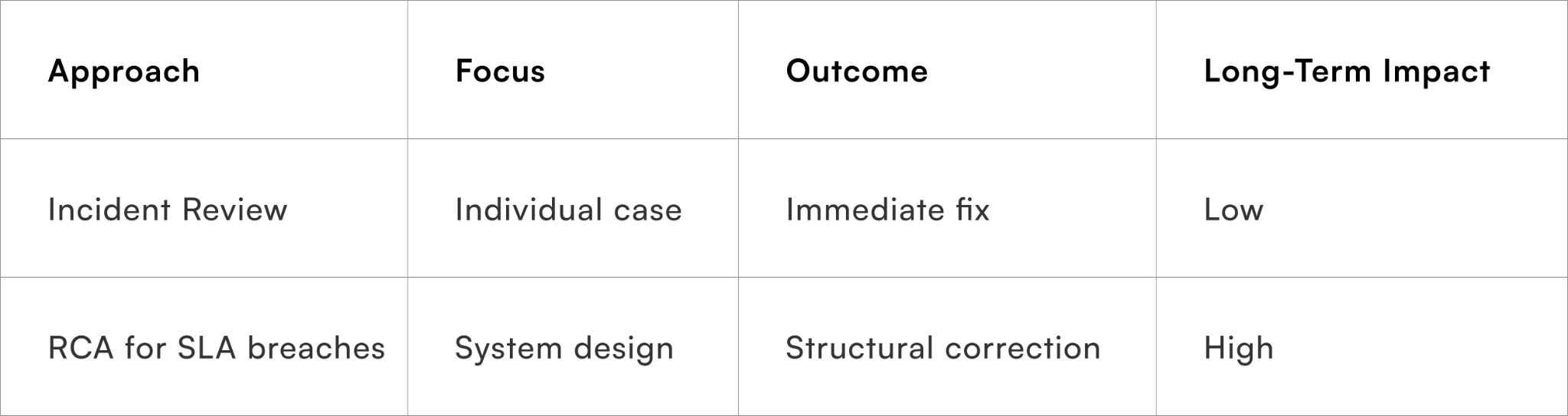
When teams formalise RCA for SLA breaches, they move from reaction to prevention.
Why does poor SLA monitoring in customer support amplify breach cycles?
Visibility gaps prevent early intervention
Effective RCA depends on accurate detection. Without disciplined SLA monitoring in customer support, teams only discover breaches after they occur.
Common monitoring gaps include:
- No early warning thresholds (e.g., 70% of SLA time elapsed)
- Static dashboards reviewed weekly instead of daily
- No segmentation by ticket category or channel
- Lack of breach pattern tracking by agent or queue
These gaps delay intervention.
Consider this structural impact:
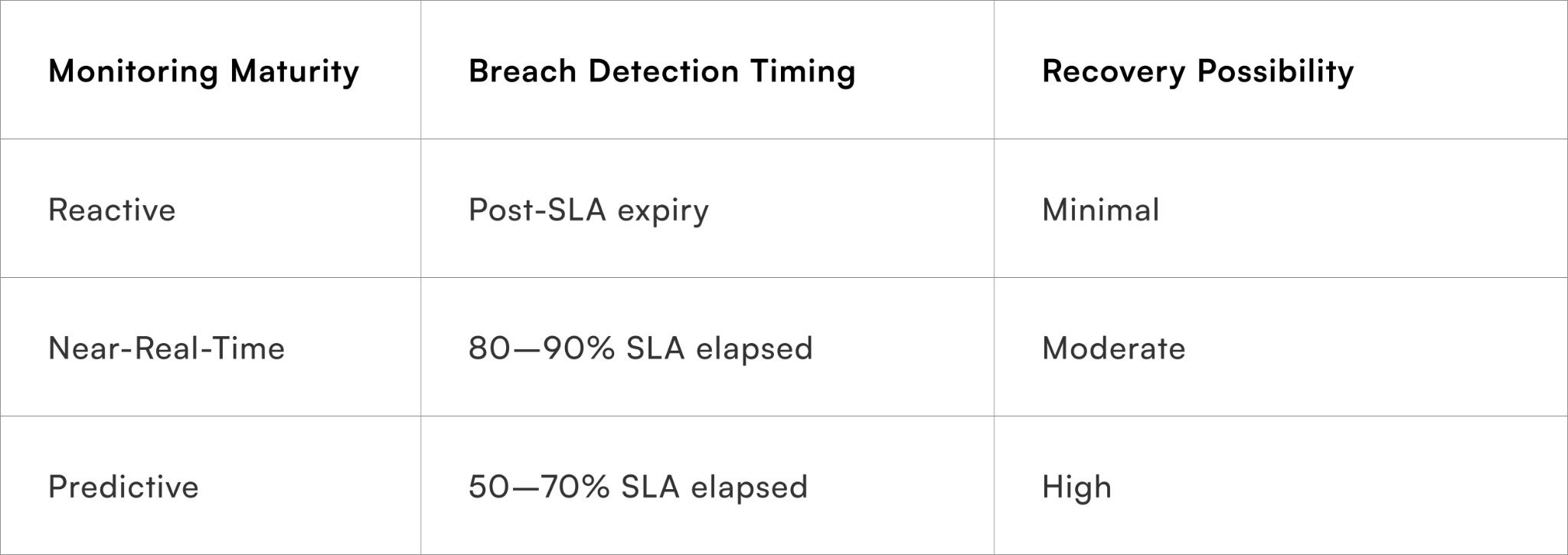
Teams investing in stronger visibility frameworks often reference structured approaches outlined in SLA breach detection methodologies. Detection speed determines whether breaches are contained or repeated.
Without early signals, RCA becomes retrospective instead of preventive.
How does repeat SLA violation analysis uncover systemic bottlenecks?
Patterns reveal friction across teams and tools
When analysing repeat breaches, isolate patterns across three dimensions:
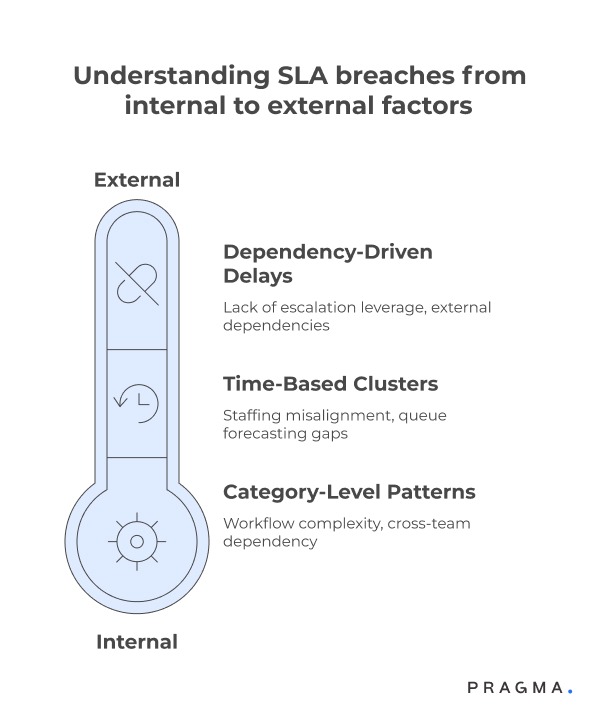
1. Category-Level Patterns
Are delays concentrated in:
- Refund queries?
- Logistics escalations?
- Damaged product complaints?
Recurring breaches within a category often signal workflow complexity or cross-team dependency.
2. Time-Based Clusters
Do breaches spike:
- During peak sale periods?
- On weekends?
- At shift transitions?
This often indicates staffing misalignment or queue forecasting gaps.
3. Dependency-Driven Delays
Certain tickets depend on:
- Carrier confirmations
- Warehouse validation
- Payment reconciliation
In these cases, SLA breach root cause analysis often reveals that support agents lack escalation leverage.
Carrier-related friction, for example, mirrors structural challenges often discussed in why carrier escalations fail and how to fix them, where delays compound due to unclear ownership and weak escalation paths.
Repeat violations rarely originate inside a single team. They emerge at workflow intersections.
Why does SLA breach root cause analysis fail without cross-functional ownership?
RCA collapses when accountability is fragmented
Support teams cannot fix breaches rooted in logistics or payments alone. Yet many organisations expect CX to “solve” SLA performance issues.
Effective root cause analysis of SLA breaches requires:
- CX ownership of detection
- Ops ownership of dependency resolution
- Clear escalation ladders
- Shared SLA dashboards
When RCA findings are not translated into cross-team action plans, documentation accumulates but performance does not improve.
Compare outcomes:

Structural correction requires alignment beyond ticket queues.
How can structured SLA monitoring frameworks prevent recurrence?
Prevention systems outperform post-breach correction
Prevention begins with layered tracking:
- Queue-level SLA compliance
- Agent-level response time trends
- Category-specific breach frequency
- Escalation response timelines
Teams that embed structured tracking models similar to frameworks explored in SLA tracking often detect repeat patterns before they escalate.
When monitoring evolves from reporting to forecasting, breaches decline predictably.
Root cause analysis for SLA violations is most powerful when combined with forward-looking metrics. Without that, teams remain in reactive cycles.
How can you build a practical root cause analysis for SLA violations playbook?
Standardised diagnosis converts recurring breaches into structural fixes
A repeat breach is rarely caused by a single breakdown. It is usually the final visible symptom of upstream friction accumulating across routing logic, staffing, tooling, and inter-team dependencies. A practical playbook for root cause analysis for SLA violations must therefore move beyond documenting what happened and instead interrogate how the system allowed delay to become inevitable.
Start by separating signal from noise. Not every breach requires deep RCA. Focus on patterns categories or queues where SLA misses recur over a defined period. The objective is not volume reduction alone, but recurrence elimination.
A strong playbook follows three disciplined layers.
First, breach clustering. Instead of analysing isolated tickets, group violations by category, time window, and dependency type. When multiple breaches share structural similarities for instance, refund approvals delayed due to finance confirmation you are likely looking at a systemic choke point rather than individual performance gaps.
Second, process mapping. Document the exact lifecycle of a ticket within the affected category. Where does it wait? Who owns it at each stage? What triggers escalation? This exercise frequently reveals “invisible idle time” periods where no one actively works on the ticket, yet SLA time continues to elapse.
Third, corrective redesign. The goal is not to add reminders or warnings. It is to change the workflow itself adjust routing rules, redefine ownership, introduce early escalation thresholds, or rebalance staffing.
When implemented consistently, RCA for SLA breaches transforms from retrospective reporting into an operational design function.
When should you use 5 Whys versus Fishbone in SLA breach root cause analysis?
Choose the method based on system complexity
Method selection matters. Not every recurring issue demands a complex diagnostic model. Over-engineering analysis wastes time; under-analysing perpetuates recurrence.
The 5 Whys framework works best when the breach pattern appears linear. For example, response times increase because ticket volume spikes during campaign days. Asking “why” repeatedly often uncovers predictable issues such as forecasting gaps or inadequate shift planning. In such cases, the causal chain is sequential and can be traced quickly.
Fishbone (Ishikawa) analysis becomes more valuable when causes are multi-dimensional. Consider a scenario where logistics-related tickets consistently breach SLA. Delays may stem from carrier response latency, unclear escalation matrices, agent training gaps, and CRM tagging errors simultaneously. Here, causes interact rather than stack linearly.
Use 5 Whys when:
- The breach pattern is new
- The workflow is relatively simple
- A single dependency appears dominant
Use Fishbone when:
- Breaches span multiple teams
- Tooling, staffing, and process intersect
- Past fixes have failed
The sophistication of your SLA breach root cause analysis should match the complexity of the operational environment. Simplicity applied correctly is more powerful than complexity applied loosely.
Why do structural fixes fail after root cause analysis of SLA breaches?
Diagnosis without governance rarely sustains improvement
Many organisations conduct thorough analysis yet see little long-term change. The failure is rarely analytical it is governance-related.
Once root causes are identified, they must translate into operational redesign with ownership and timelines. Without this transition, RCA becomes documentation rather than intervention.
Common breakdowns include:
- No assigned implementation owner
- No deadline for workflow modification
- No measurement of post-fix performance
- No audit of recurrence within 30–60 days
For example, if RCA reveals that tickets remain idle awaiting carrier confirmation, the structural fix may involve redefining escalation protocols. If that change is not formally embedded into SOPs and monitored, agents revert to prior behaviour under pressure.
This is particularly visible in logistics-dependent queues, where escalation inefficiencies mirror patterns explored in [why carrier escalations fail and how to fix them]. Without structural leverage, delays persist irrespective of awareness.
Root cause analysis of SLA breaches succeeds only when corrective design is institutionalised — not suggested.
How does automation strengthen repeat SLA violation analysis?
Early detection reduces downstream firefighting
Automation should not replace analysis; it should enhance detection and containment. When combined with disciplined SLA monitoring in customer support, automation becomes an early-warning system rather than a reactive reporting layer.
Consider the lifecycle of a high-risk ticket. If systems trigger alerts at 70% of SLA consumption, supervisors can intervene before expiry. This transforms RCA from post-mortem exercise into preventive action.
Advanced automation can also surface recurring patterns:
- Categories with rising breach frequency
- Agents with disproportionate delay clusters
- Time-of-day breach spikes
- Escalations exceeding response thresholds
Frameworks such as SLA breach detection highlight the importance of near-real-time monitoring, but the strategic advantage lies in linking detection data directly into RCA workflows.
When breach data flows automatically into monthly pattern reviews, teams can conduct structured repeat SLA violation analysis with empirical evidence rather than anecdotal assumptions.
Automation accelerates visibility. Analysis converts visibility into correction.
When should you prioritise structural fixes over staffing adjustments?
Capacity expansion rarely solves process inefficiency
A common reaction to repeated SLA breaches is to increase headcount. While staffing imbalances can contribute to delays, capacity expansion should not precede structural validation.
If process design is flawed, additional agents only accelerate inefficient workflows. Tickets still route incorrectly. Dependencies still stall. Escalations remain unclear.
Before adjusting staffing models, examine:
- Average handling time variance by category
- Idle time between ticket states
- Escalation turnaround gaps
- Queue-level load distribution
If breaches correlate strongly with volume spikes alone, capacity recalibration may be justified. However, if breaches persist during normal load periods, the issue is structural.
Teams implementing disciplined repeat SLA violation analysis often discover that workflow redesign reduces breach rates more sustainably than hiring alone.
Structural fixes scale. Headcount increases plateau.
Why does SLA monitoring maturity determine RCA effectiveness?
Visibility depth shapes analytical accuracy
Root cause analysis depends on reliable data. If monitoring systems only capture final SLA status, analysis becomes speculative. Mature SLA monitoring in customer support captures progression states, elapsed time segments, and escalation timestamps.
This level of granularity enables more precise diagnosis. For instance, if data reveals that 60% of elapsed time occurs before first agent touch, routing logic becomes suspect. If most delay accumulates post-escalation, inter-team coordination requires redesign.
Organisations evolving their monitoring capabilities — often beginning with structured tracking frameworks such as SLA tracking typically experience sharper RCA outcomes because data precision narrows diagnostic ambiguity.
When monitoring maturity increases, RCA shifts from assumption-based reasoning to evidence-based redesign.
How can you institutionalise root cause analysis for SLA violations in 30 days?
Structured weekly execution builds prevention discipline
Sustainable improvement requires moving RCA from occasional exercise to embedded operating rhythm. The next 30 days should focus on institutionalising structure rather than attempting sweeping transformation.
Week 1: Establish breach visibility and clustering
Extract the last 60–90 days of SLA data. Segment breaches by:
- Ticket category
- Escalation dependency
- Time of day
- Channel
Identify the top three recurring breach clusters. Avoid analysing everything at once. Focus on repeat patterns that materially impact customer experience.
Define ownership for each cluster and schedule structured RCA sessions. This prevents analysis from remaining abstract.
Expected result: Clear prioritisation of high-impact recurrence zones.
Week 2: Conduct structured RCA workshops
For each cluster, run a 60-minute session with cross-functional representation where required. Use 5 Whys for linear problems and Fishbone where interdependencies exist.
Document:
- Structural cause
- Trigger failure point
- Workflow bottleneck
- Escalation delay
Translate findings into redesign decisions immediately. Avoid ending sessions with observations alone.
This is where disciplined root cause analysis of SLA breaches moves from discussion to system correction.
Expected result: Actionable redesign decisions tied to ownership and timelines.
Week 3: Redesign workflows and embed monitoring controls
Update SOPs, routing rules, and escalation ladders based on findings. If required, introduce early-warning thresholds in your dashboards.
Strengthen SLA monitoring in customer support by adding:
- 70% SLA consumption alerts
- Queue-level ageing visibility
- Escalation turnaround tracking
This ensures recurrence is detected before it compounds.
Where detection capability is weak, frameworks such as SLA breaches in e-commerce often highlight structural blind spots that delay intervention.
Expected result: Improved breach containment and fewer last-minute escalations.
Week 4: Audit recurrence and reinforce governance
After implementation, measure:
- Breach recurrence rate within the corrected category
- Time-to-resolution trends
- Escalation turnaround consistency
If recurrence persists, revisit structural assumptions rather than reverting to staffing adjustments.
Institutionalisation requires rhythm. Schedule a monthly repeat SLA violation analysis review to prevent drift.
Expected result: Declining breach recurrence and stronger cross-team accountability.
Which metrics define effective SLA breach root cause analysis?
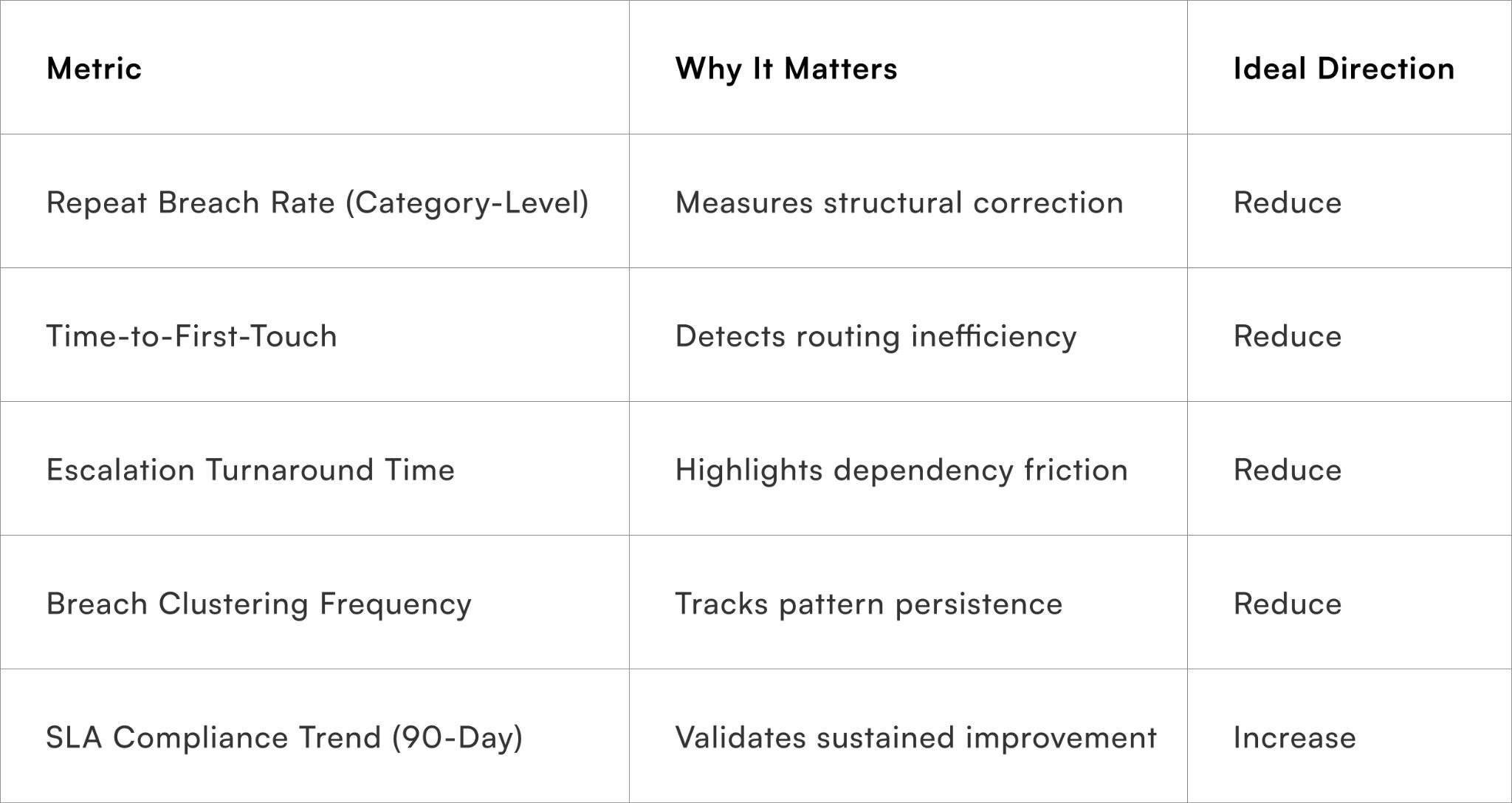
Measure recurrence, not just resolution
Resolution metrics alone do not validate RCA success. You must track recurrence decline and structural correction.
Core RCA Effectiveness Metrics
Advanced Insight Layer
Break metrics by:
- Channel (email, chat, social)
- Shift timing
- Agent tenure
- Dependency team
When detection capability improves — as seen in structured SLA breach detection environments RCA becomes predictive rather than reactive.
Effective root cause analysis for SLA violations reduces recurrence over quarters, not days.
To Wrap It Up
Repeat SLA violations are rarely accidental. They are structural signals indicating workflow friction, dependency gaps, or monitoring immaturity. Sustainable correction demands disciplined, recurring analysis — not episodic firefighting.
Select one high-frequency breach category this week and run a structured RCA session with clear implementation ownership.
Over the long term, institutionalising governance, embedding predictive monitoring, and reviewing recurrence trends quarterly will compound operational resilience. RCA should evolve from reactive analysis to preventive design capability.
For D2C brands seeking stronger SLA governance and predictive breach visibility, Pragma's SLA intelligence platform provides structured monitoring, automated breach detection, and workflow analytics that help teams reduce recurrence rates and improve sustained SLA compliance.
.gif)
FAQs (Frequently Asked Questions On Root-cause analysis playbook for repeat SLA violations)
1. What is root cause analysis for SLA violations?
Root cause analysis for SLA violations involves identifying the underlying reasons behind missed service-level targets. It helps teams move beyond symptoms and fix systemic issues.
2. How does RCA for SLA breaches improve operations?
RCA for SLA breaches uncovers patterns in delays, process gaps, or performance bottlenecks. This enables teams to implement targeted fixes and prevent recurrence.
3. What are common causes identified in root cause analysis of SLA breaches?
Common causes include process inefficiencies, system delays, staffing gaps, and data inaccuracies. Identifying these drivers helps prioritise corrective actions.
4. How to perform repeat SLA violation analysis effectively?
Repeat SLA violation analysis involves tracking recurring issues across time, regions, or workflows. This helps identify systemic failures rather than isolated incidents.
5. What steps are included in an SLA breach root cause analysis playbook?
Steps include data collection, pattern identification, hypothesis testing, and corrective action planning. A structured approach ensures consistent and actionable insights.
6. How does SLA monitoring in customer support support RCA?
SLA monitoring in customer support provides real-time visibility into performance metrics. This enables early detection of breaches and faster root cause identification.
7. Can automation improve root cause analysis for SLA violations?
Yes, automation can detect anomalies, highlight trends, and generate insights from large datasets. This speeds up analysis and improves accuracy.
8. What are the benefits of a strong RCA framework for SLA breaches?
Benefits include reduced repeat violations, improved service quality, and better operational efficiency. It also enhances accountability and continuous improvement.
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo


.png)