

Most D2C brands don’t suffer from a lack of logistics partners. They suffer from using the same partners in the same way, even when conditions change. A courier that performs reliably for apparel in metro pincodes during regular weeks can break down completely for bulky SKUs in the same region during festive surges or monsoon months. Yet partner switches are often reactive, manual, and inconsistent.
Region + SKU + season triage: rules for switching partners dynamically examines how operations teams can formalise these decisions instead of firefighting them. Rather than relying on blanket carrier changes or ad-hoc escalations, this approach treats partner switching as a structured triage problem driven by context.
By combining regional constraints, SKU-level delivery behaviour, and seasonal volatility into clear rules, teams can anticipate when a partner is likely to underperform and switch early. The outcome is not constant churn, but smarter, limited switching that protects SLAs, controls cost, and keeps delivery promises credible even during high-variance periods.
Why does partner performance vary by region, SKU, and season?
Contextual stress reveals weaknesses static routing hides
Regional constraints amplify SKU-level complexity
A carrier’s performance is deeply shaped by local last-mile realities. The same SKU can behave very differently depending on where it is delivered.
High-rise metros introduce access and timing constraints, while semi-urban regions struggle with hub distance and manpower availability. When SKU characteristics such as size, fragility, or COD dependency intersect with these regional constraints, failure probability rises sharply.
Common regional stress factors include:
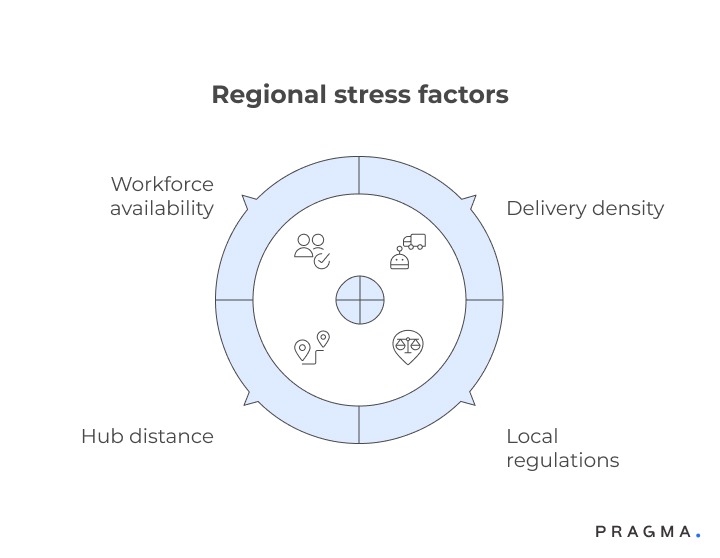
- Delivery density and route complexity
- Local regulations or security restrictions
- Hub distance and line-haul reliability
- Workforce availability and attrition
Why regional averages mislead routing decisions
National or state-level metrics flatten local variation and mask pincode-level stress points.
How do SKU characteristics influence partner suitability?
Not all products behave equally in transit
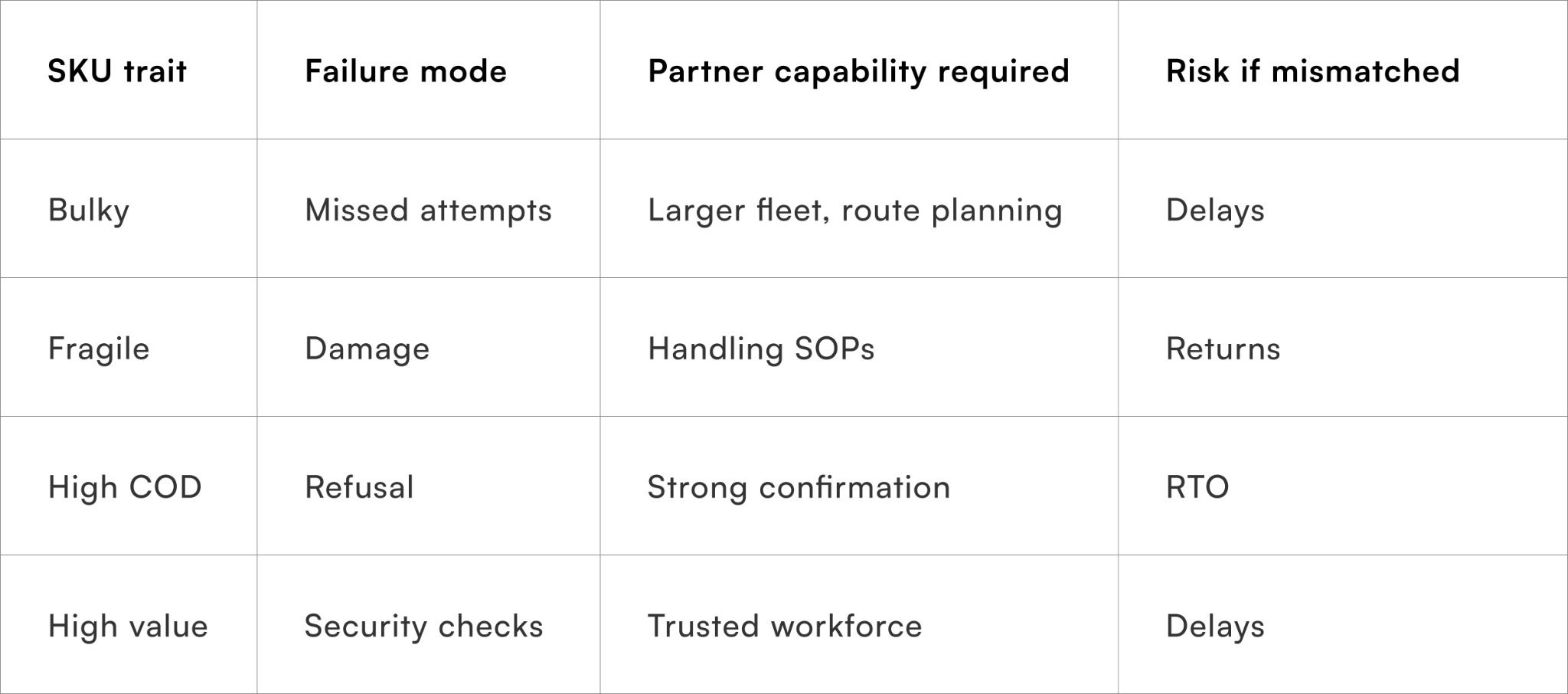
Identifying SKUs that magnify delivery risk
Certain SKU traits consistently increase delivery friction. Bulky products slow last-mile execution, fragile items increase handling errors, and high-value SKUs attract stricter checks or customer unavailability. When these SKUs are routed through partners optimised for speed rather than care, performance drops.
High-risk SKU traits typically include:
- Oversized or irregular packaging
- Fragile or liquid contents
- High COD value or prepaid fraud sensitivity
- Made-to-order or low-margin items
Why SKU-blind routing inflates operational cost
Using a single “best” carrier ignores how different products stress the network differently.
How do you operationalise triage without slowing down dispatch?
Good rules are useless if they delay decisions at scale
One of the biggest concerns with dynamic switching is speed. Introducing more logic into routing decisions can easily become a bottleneck if every shipment requires evaluation at dispatch time.
The way to avoid this is by shifting triage from real-time decision-making to pre-computed readiness.
Instead of evaluating every order from scratch, teams can:
- Predefine high-risk region–SKU combinations
- Attach routing preferences to these segments in advance
- Refresh these rules periodically (daily or weekly, not per order)
At dispatch, the system isn’t “thinking” — it’s simply applying pre-approved logic.
For example, if bulky furniture shipments to specific pincodes are already flagged as high-risk during monsoon weeks, the routing layer can automatically prioritise alternate partners without delay. No manual override, no additional computation.
This separation between rule creation (offline) and rule execution (real-time) keeps operations fast while still allowing context-aware decisions.
Over time, this also reduces dependency on ops teams constantly monitoring dashboards. The system becomes proactive, not reactive — but without adding friction to fulfilment speed.
How should cost be balanced against SLA during partner switching?
The fastest option isn’t always the most sustainable one
Switching partners often improves SLA performance, but it can also increase cost — sometimes significantly. If every delay triggers a move to a premium carrier, margins erode quickly.
The challenge is not choosing between cost and SLA, but defining acceptable trade-offs for different scenarios.
High-impact cases justify higher cost:
- High-value orders where delay risks cancellation
- First-time customers where experience matters more
- Time-sensitive SKUs (gifts, perishables, launches)
Lower-impact segments can tolerate slower recovery:
- Low-margin products
- Repeat customers with predictable behaviour
- Regions where minor delays are common and accepted
Instead of treating cost as a static constraint, it becomes a controlled variable within triage rules.
For instance, a rule might allow switching to a higher-cost partner only if:
- SLA breach risk crosses a threshold
- AND order value exceeds a defined limit
This ensures that switching decisions remain economically rational, not just operationally convenient.
Over time, this approach prevents a common failure mode:
fixing delivery reliability at the expense of profitability.
What role does partner specialisation play in dynamic switching?
Not all carriers are generalists — and routing should reflect that
Most logistics partners are not equally good at everything. Some are optimised for speed in metros, others for deep reach in remote regions, and some for handling bulky or sensitive shipments.
Dynamic switching becomes far more effective when it leans into these strengths instead of treating partners as interchangeable.
In practice, this means mapping partners to specific capabilities:
- High-density urban delivery
- Remote or low-density coverage
- Bulky or heavy shipments
- High COD handling reliability
Once this mapping is clear, switching is no longer just a reaction to failure — it becomes a redistribution toward better fit.
For example, if a partner consistently struggles with oversized shipments in certain regions, the triage system doesn’t just switch away during failure. It gradually reduces exposure for that SKU category altogether.
This reduces repeated firefighting and creates a more stable routing baseline over time.
Instead of asking “who is fastest right now?”, teams start asking:
“who is best suited for this type of shipment under these conditions?”
How do you prevent internal teams from overriding triage rules?
The biggest threat to structured systems is ad hoc human intervention
Even well-designed switching frameworks can break down if teams frequently override them. This usually happens when:
- Ops teams don’t trust the rules yet
- CX escalations push for immediate exceptions
- Short-term pressure overrides long-term logic
While some level of manual control is necessary, excessive overrides quickly undo the consistency triage is meant to create.
The solution isn’t to remove control, but to make overrides visible and accountable.
A few practical approaches:
- Log every manual routing override with a reason
- Track how often overrides outperform or underperform rules
- Restrict full overrides to specific roles or scenarios
When teams can see that rules are working — and that overrides don’t always perform better — trust builds naturally.
At the same time, this creates a feedback loop. If certain overrides consistently outperform existing rules, they can be formalised into the system instead of remaining one-off decisions.
The goal isn’t rigid automation. It’s controlled flexibility, where human intervention improves the system instead of bypassing it.
How does dynamic switching impact customer experience beyond delivery speed?
Switching isn’t invisible — it affects communication, predictability, and trust
While most discussions focus on SLA improvement, partner switching also has subtle effects on the customer experience.
Different carriers behave differently from a customer’s perspective:
- Tracking link formats and update frequency
- Delivery attempt communication
- Calling behaviour before arrival
- Payment handling (especially COD)
Frequent or inconsistent switching can create confusion if not managed carefully. A customer expecting one type of communication flow may suddenly experience another.
To avoid this, switching logic should consider not just operational performance, but also experience consistency.
For high-touch orders, this might mean:
- Preferring partners with better communication quality
- Avoiding last-minute switches after shipment is visible to the customer
- Aligning tracking and notification flows as much as possible
This becomes especially important for repeat customers, where inconsistency is more noticeable than delay.
In the long run, the goal is not just faster delivery, but predictable delivery behaviour — where customers know what to expect, even if the underlying partner changes.
What seasonal patterns most distort partner performance?
Volume spikes and environmental factors change the rules
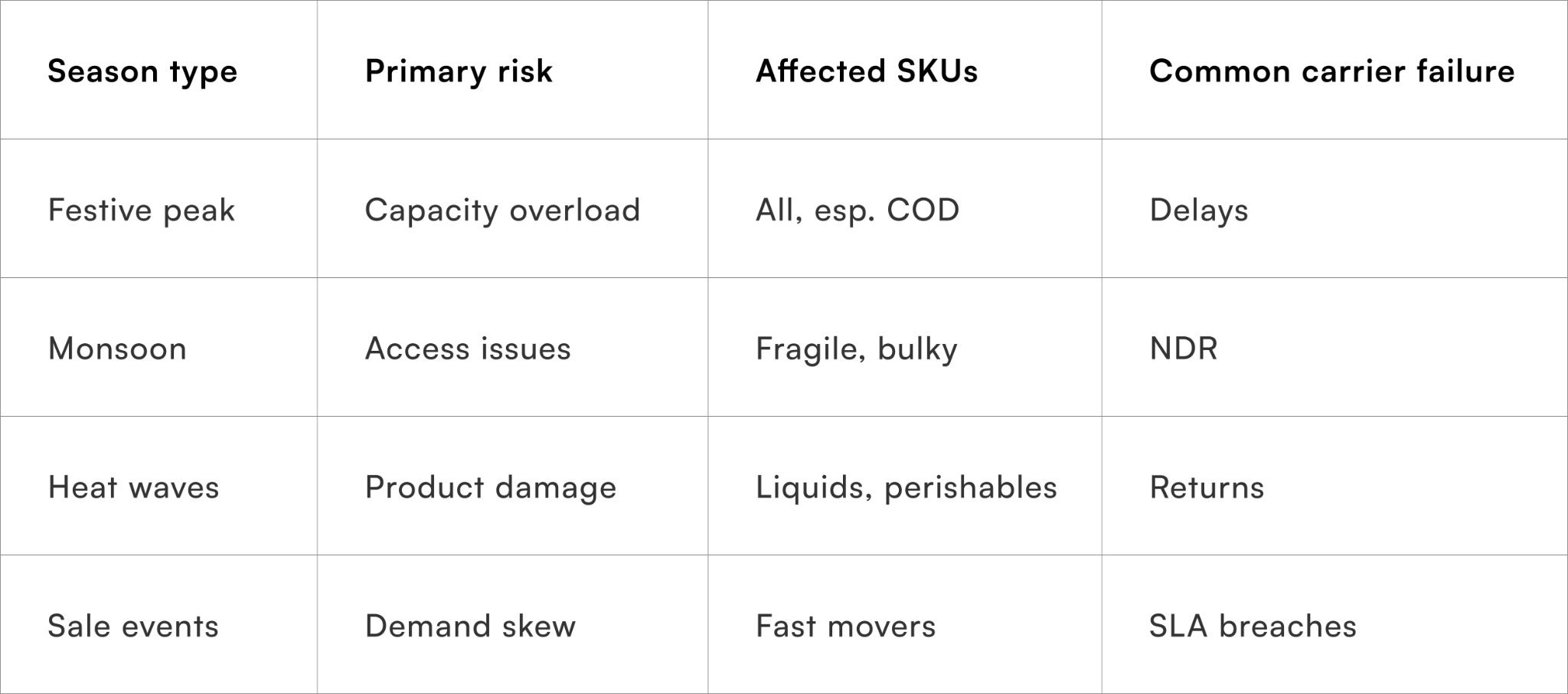
Separating predictable seasonality from true shocks
Festive sales, monsoons, and regional events introduce predictable stress patterns. Carriers may add temporary capacity, but quality often degrades under sustained volume pressure. Environmental factors such as flooding or heatwaves further affect last-mile execution, especially for fragile or time-sensitive SKUs.
Key seasonal disruptors include:
- Festival-driven volume surges
- Weather-related access issues
- Temporary workforce churn
- Promotional demand skewed to select regions
Why seasonality requires pre-emptive switching
Waiting for metrics to degrade means reacting after customer impact has already occurred.
How do these three dimensions interact in practice?
Why single-factor rules fail
Understanding compounding risk
The real risk emerges when region, SKU, and season overlap. A fragile SKU in a flood-prone region during monsoon carries exponentially higher risk than any single factor suggests. Static routing rules cannot capture this compounding effect.
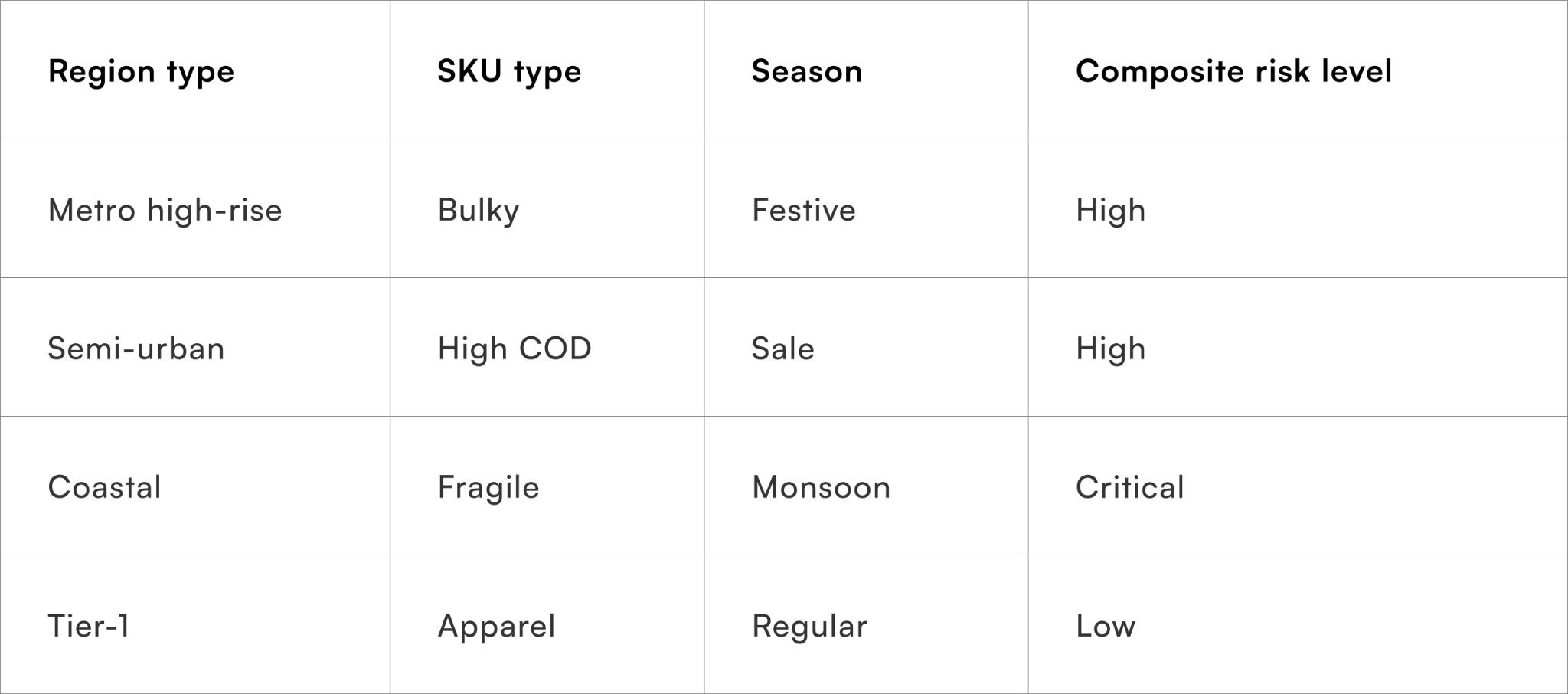
Why triage must be multi-dimensional
Only by evaluating all three inputs together can teams switch partners selectively instead of broadly.
How can triage rules decide when to switch partners?
Turning context into deterministic switching logic
Defining switch triggers instead of reactive escalations
Dynamic partner switching works only when triggers are defined before performance collapses. These triggers should combine leading indicators (that signal rising stress) with outcome thresholds (that confirm sustained degradation). This avoids both premature switching and late reaction.
Common high-signal switch triggers include:
- Sustained delay in first-attempt success for a region–SKU pair
- Spike in address or access-related NDRs beyond baseline
- Seasonal load crossing carrier-specific capacity thresholds
- Repeated manual interventions by ops or CX for the same segment
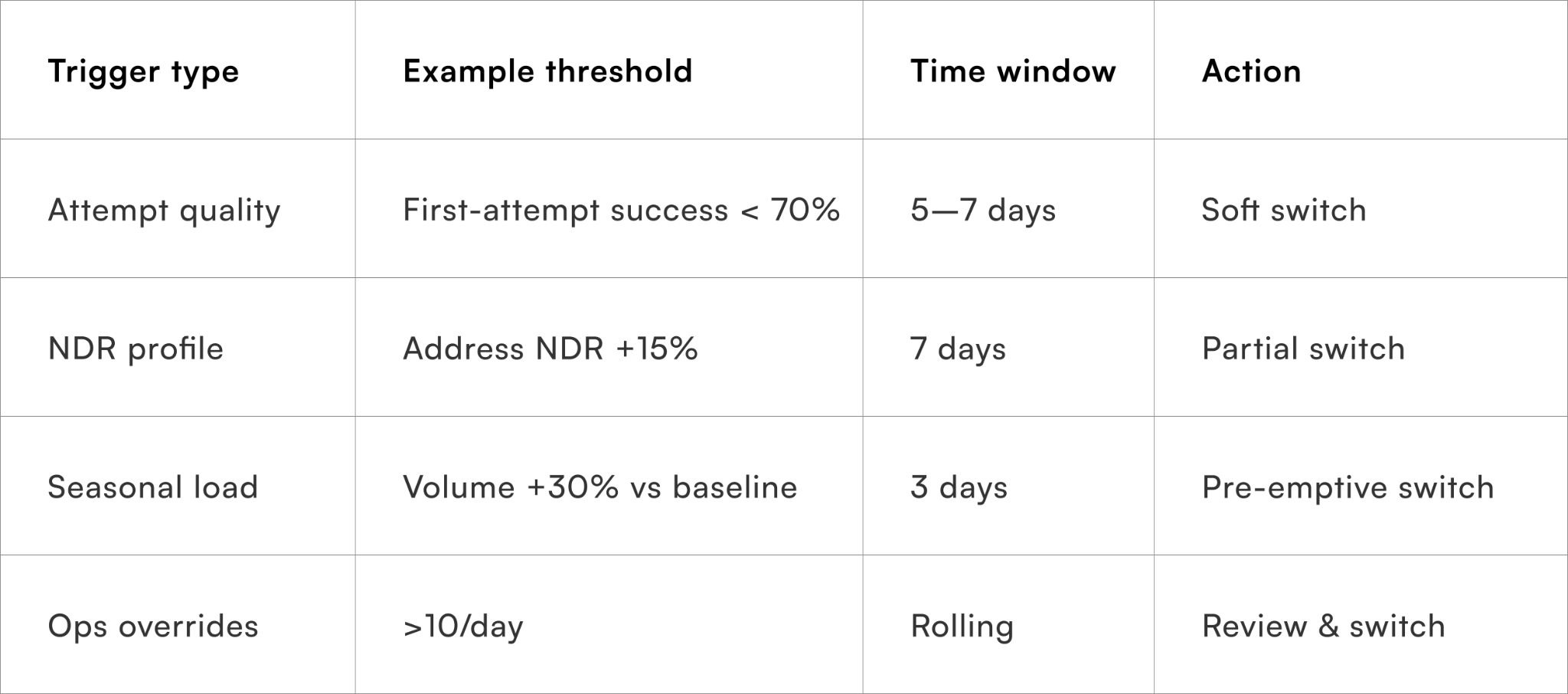
Why triggers should favour trend over spikes
Single-day anomalies often self-correct; sustained patterns rarely do.
How should switch intensity be controlled?
Avoiding churn while protecting SLAs
Using graduated switching instead of binary decisions
All-or-nothing switching increases volatility and damages partner relationships. Effective triage uses graduated intensity, starting with partial redistribution and escalating only if performance fails to recover.
Typical switch intensities:
- Soft switch: divert 20–30% volume
- Partial switch: cap primary partner at 50–60%
- Full switch: temporary freeze with review trigger
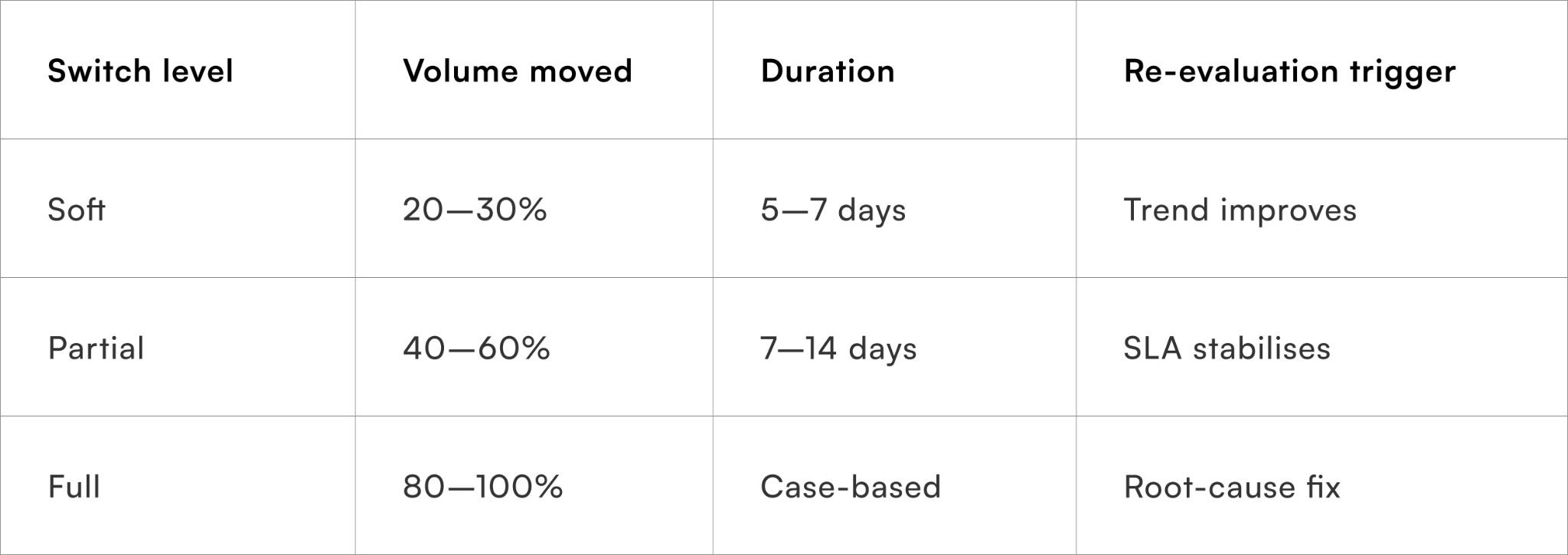
Why reversible switches preserve optionality
Reversibility allows teams to respond quickly without burning long-term capacity.
How do guardrails prevent over-switching?
Stability is as important as responsiveness
Embedding limits into triage logic
Without guardrails, even well-designed rules can cause excessive churn during volatile periods. Guardrails ensure switching remains deliberate and explainable.
Common guardrails include:
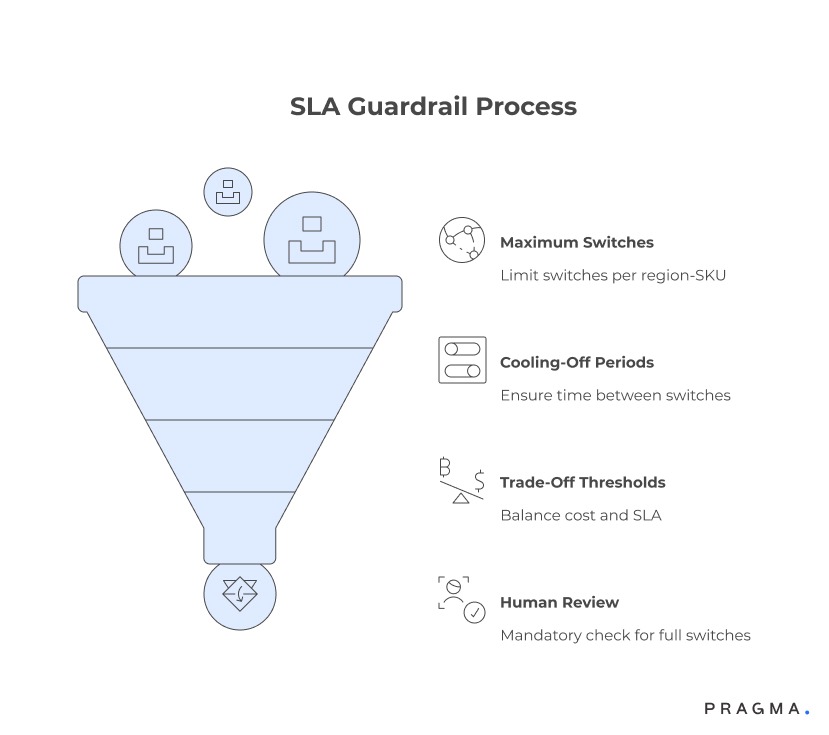
- Maximum switches per region–SKU per month
- Minimum cooling-off periods between switches
- Cost and SLA trade-off thresholds
- Mandatory human review for full switches
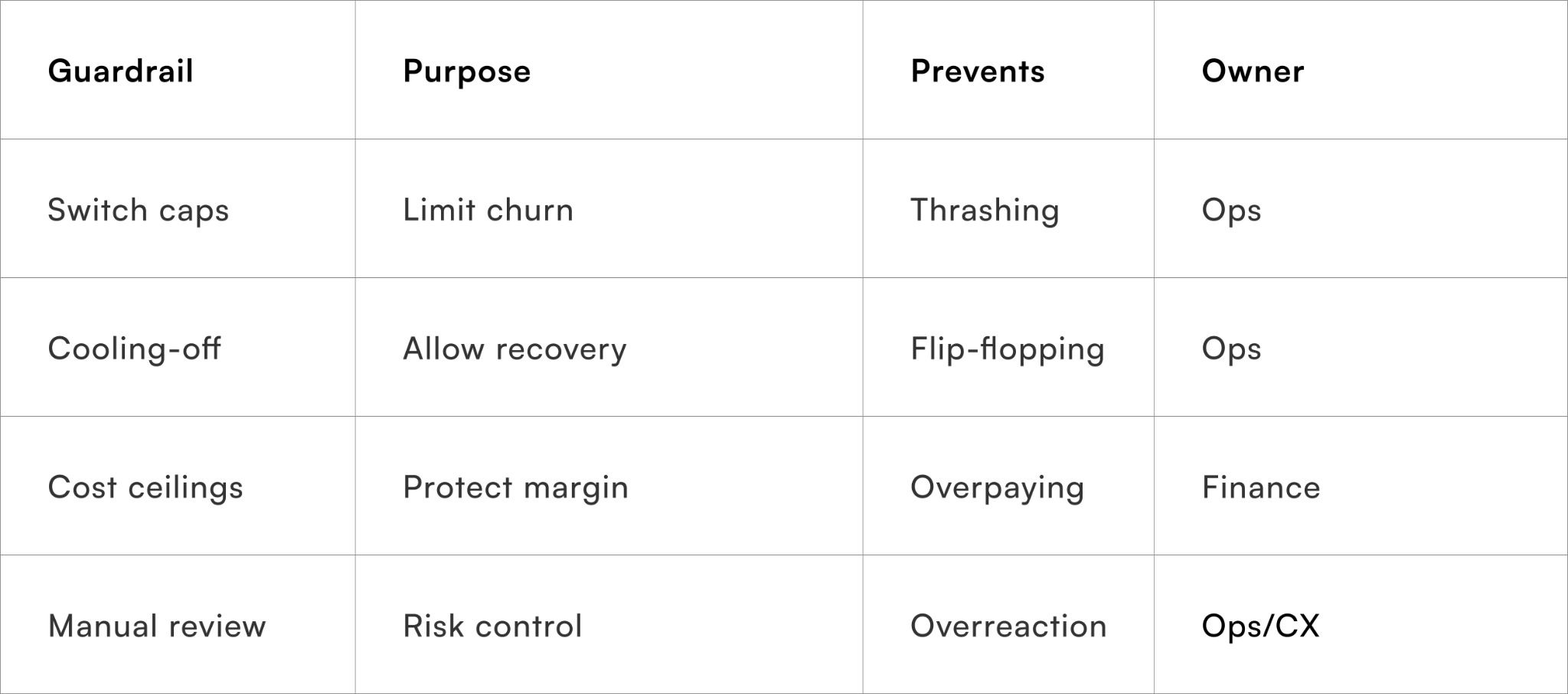
Why guardrails build partner and internal trust
Predictable behaviour keeps partners engaged and teams confident.
How should outcomes feed back into triage rules?
Learning from every switch
Measuring switch effectiveness, not just performance
Each switch is a hypothesis. The feedback loop must capture whether switching improved outcomes for that specific context, not just overall metrics.
Feedback should evaluate:
- SLA recovery speed post-switch
- Cost impact versus baseline
- CX ticket reduction
- Partner-specific recovery patterns

Why feedback should refine rules, not just reports
The goal is to reduce future switches, not document past ones.
Quick Wins
Launching dynamic partner switching without destabilising operations
Week 1: Identify triage-ready segments
Pull the last 90 days of data and tag combinations where region + SKU + season repeatedly coincide with SLA breaches or high NDR volume. Limit the first rollout to 5–8 high-impact segments.
By week’s end, teams usually uncover a small set of combinations driving most escalations.
Week 2: Define switch triggers and guardrails
Lock 2–3 leading indicators per segment and agree on soft and partial switch thresholds. Add cooling-off periods and switch caps to avoid churn.
This ensures the rules are decisive without becoming volatile.
Week 3: Pilot graduated switching
Enable soft switches (20–30% volume shifts) for one or two segments during live operations. Track outcomes daily but intervene only if trends persist.
Most teams see early SLA stabilisation without full partner changes.
Week 4: Close the feedback loop
Compare outcomes before and after switches. Adjust thresholds conservatively and document learnings for the next seasonal cycle.
At 30 days, switching decisions become predictable instead of reactive.
Metrics to monitor dynamic switching effectiveness
Ensuring triage improves outcomes, not just activity

These metrics keep the triage framework outcome-driven rather than rule-driven.
To Wrap It Up
Dynamic partner switching works when it is treated as a triage problem, not a panic response. By combining region, SKU behaviour, and seasonality into structured rules, teams can switch early, limit impact, and avoid blanket changes.
This week, identify one high-risk region–SKU combination and pilot a soft switch with clear thresholds.
Over time, disciplined feedback and conservative calibration ensure switching becomes rarer, smarter, and more predictable across seasons.
For D2C brands seeking context-aware logistics orchestration, Pragma’s orchestration platform enables rule-based switching, outcome tracking, and continuous optimisation that help brands protect SLAs and control costs even under volatile conditions.
.gif)
FAQs (Frequently Asked Questions On Region + SKU + season triage: rules for switching partners dynamically)
1. What is Region + SKU + Season triage in logistics?
It is a rule-based framework that adjusts delivery partners based on location, product type, and seasonal demand.This approach improves delivery success and operational efficiency.
2. Why is dynamic partner switching important?
It allows businesses to respond quickly to changing delivery conditions and partner performance.This reduces delays, failures, and customer dissatisfaction.
3. How does region impact partner selection?
Different regions have varying infrastructure, accessibility, and courier reliability.
Selecting partners based on regional performance improves delivery outcomes.
4. What role does SKU play in triage decisions?
SKU characteristics like size, value, and fragility influence courier suitability.
Certain partners perform better for specific product categories.
5. How does seasonality affect logistics performance?
Peak seasons can strain courier capacity and increase delays.
Dynamic switching helps maintain service levels during high-demand periods.
6. What rules are used for switching delivery partners?
Rules typically include performance thresholds, delivery success rates, and SLA adherence.
Triggers activate switching when metrics fall below acceptable levels.
7. Can this triage system reduce delivery failures?
Yes, it proactively routes shipments to better-performing partners.
This significantly lowers failure and return rates.
8. How often should partner switching rules be updated?
Rules should be reviewed regularly using real-time and historical data.
Frequent updates ensure relevance and accuracy.
9. Is automation required for dynamic switching?
Automation is highly recommended to enable real-time decision-making at scale.
Manual processes are slower and prone to errors.
10. How does this approach benefit eCommerce businesses?
It improves delivery reliability, reduces costs, and enhances customer experience.
Businesses can scale operations more effectively.
11. What data is needed to implement triage rules?
Data such as delivery success rates, transit times, SKU attributes, and seasonal trends is essential.Accurate data ensures effective decision-making.
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo


.png)