

Your support agent receives a call from an angry customer demanding to know why their third order in two months arrived damaged again. The agent frantically clicks through multiple tabs—order management system, CRM notes, previous tickets, email history, chat transcripts—desperately trying to piece together the full story. Five minutes pass whilst the customer's frustration escalates, and the agent still hasn't found the pattern showing that all three orders shipped from the same problematic fulfillment centre.
Support teams waste countless hours daily searching for customer information, with agents spending 30-40% of their time on searches rather than problem-solving. This inflates two-minute interactions into eight-minute ordeals, compounding productivity drain and operational costs, while destroying customer satisfaction due to unnecessary wait times.
In this comprehensive guide on using AI copilot to retrieve past orders and conversations in seconds, we're diving deep into how intelligent search transforms information access from manual hunting to instant recall. Agents using AI-powered retrieval systems save up to 2 hours and 20 minutes per day on information lookup alone, enabling them to handle significantly more queries whilst providing better service through complete contextual understanding rather than fragmented knowledge.
What Is an AI Copilot in Customer Support?
An AI Copilot in customer support is an intelligent assistant that augments human agents by surfacing contextually relevant information such as past orders, conversation history, resolution outcomes and product details within seconds.
Instead of manually searching multiple systems, agents interact with a natural-language interface where a Copilot:
- Understands the intent behind queries, even if phrased conversationally
- Retrieves precise order records based on partial or ambiguous information
- Synthesises related customer history into a unified answer
- Reduces cognitive load and accelerates resolution
In practical terms, an AI Copilot acts like an expert assistant: customers ask questions as they naturally would (e.g., “Show me John’s order from last Diwali sales”), and the system responds with accurate records drawn from integrated data sources. This moves support from search + guesswork to conversation + insight.
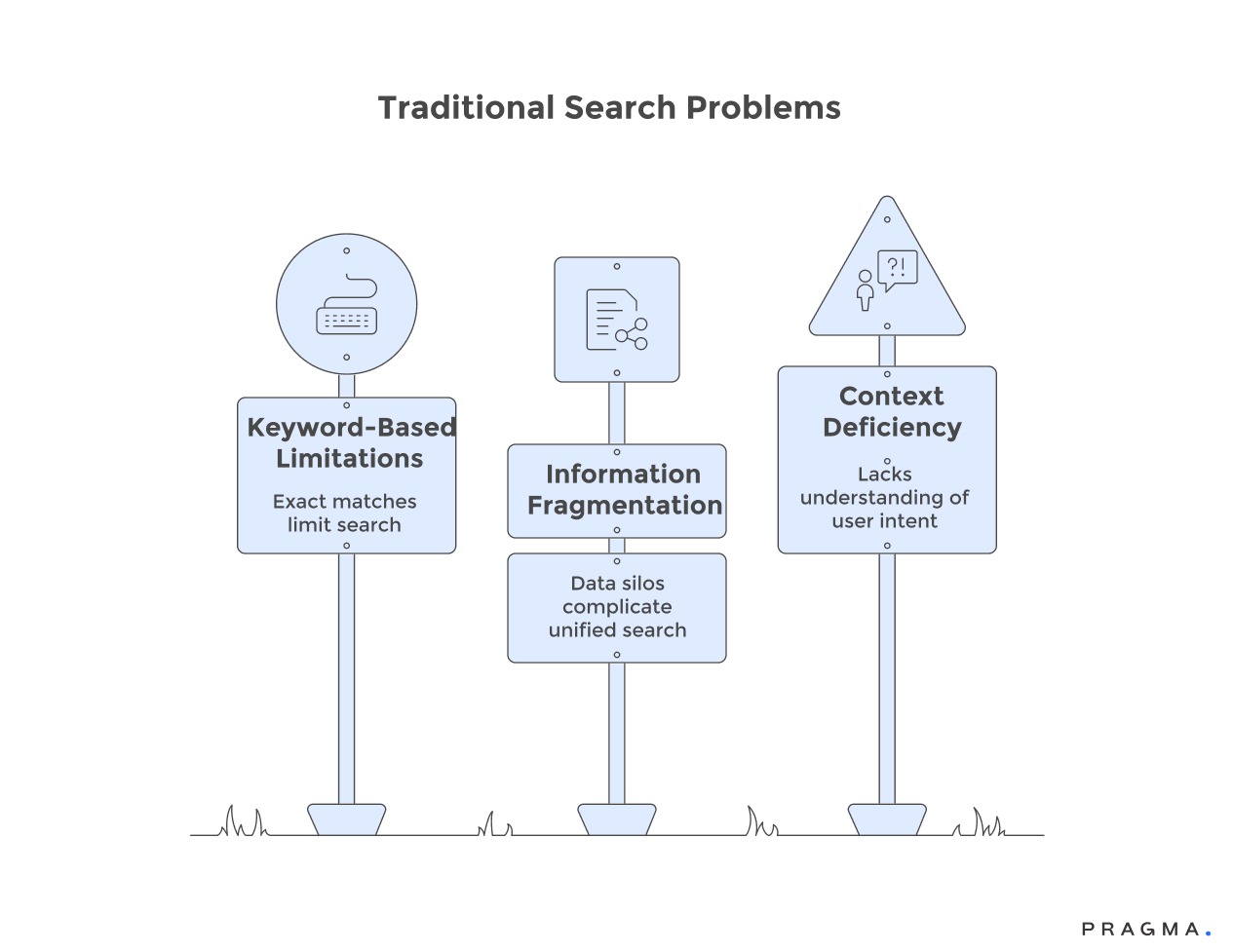
Why Traditional CRM Search Fails Support Agents
Examining the structural problems that make finding customer information unnecessarily difficult
Conventional CRM search operates like basic document retrieval—agents type keywords hoping to match exact phrases within customer records, orders, or interaction histories. This crude matching approach fails the moment agents don't know precise terminology, misremember details, or need conceptual searches beyond literal text matching.
Siloed information architecture forces agents to search multiple systems independently because customer data fragments across platforms. Order details live in e-commerce systems, support conversations reside in ticketing tools, chat histories exist separately, email threads sit in different databases, and WhatsApp interactions occupy yet another platform. Each system requires separate searches using different interfaces and query languages.
Keyword dependency creates search failure when agents lack exact words describing what they're seeking. Searching "damaged package" won't surface tickets where customers wrote "broken items," "crushed box," or "poor packaging," despite these describing identical issues requiring similar resolutions.
Chronological overload presents agents with hundreds of previous interactions sorted by date without intelligent prioritisation. When customers have lengthy interaction histories, scrolling through chronological records to find relevant context becomes impossibly time-consuming during live support calls.
Missing semantic understanding prevents systems from recognising that "Where is my shipment?" and "Track my delivery" represent identical information needs despite using completely different words. Traditional search treats these as unrelated queries requiring separate lookup attempts.
Context blindness means search results ignore current conversation topics, returning everything matching keywords rather than prioritising information relevant to the specific problem agents are currently addressing. A search for "order status" returns every order status inquiry ever made rather than focusing on recent unresolved delivery issues.
Structured data limitations restrict searches to predefined fields like order numbers, dates, or customer names, preventing agents from finding information through natural language descriptions of problems, product types, or resolution outcomes. Finding "all customers who received damaged electronics from Warehouse B in March" becomes impossible without custom report generation.
The absence of relationship mapping fails to connect related information automatically—agents manually must discover that the current complaint connects to three previous incidents, two previous replacements, and a standing quality issue with a specific product batch.
Systems & Architecture Required for AI Copilot
Implementing an AI Copilot for past-order retrieval requires a coordinated system architecture that unifies data, models and interface layers.
1. Unified Data Layer
Centralised access to:
- Order history
- Customer master records
- Support tickets
- Product catalogues
- Delivery and returns metadata
This can be a data warehouse, lakehouse or real-time data platform.
2. Semantic Index & Embeddings
AI Copilot depends on semantic representation — meaning that text, metadata and contextual features must be transformed into embeddings that a model can reason over.
These embeddings allow queries to match records by meaning rather than literal terms.
3. Natural Language Understanding Models
Pretrained language models (LLMs) fine-tuned for retrieval tasks enable:
- Intent understanding
- Paraphrase recognition
- Query expansion
This is the engine that interprets what the agent is really asking.
4. Retrieval-Augmented Generation (RAG)
RAG pipelines combine vector search with grounded data sources, ensuring that responses are both relevant and truthful rather than hallucinated.
5. API & UI Layers
A support agent interface (embedded in CRM or a shared console) where the Copilot can be invoked through text or command-like prompts, returning structured results.
6. Monitoring & Logging
Tracking query patterns, success/failure rates, latency metrics and escalation paths feeding performance insights back to engineering and ops teams.
When these systems work together, the Copilot becomes more than a search tool it becomes a context-aware assistant that accelerates support operations.
Metrics to Watch for Retrieval Performance
Measuring Copilot effectiveness goes beyond raw speed; these operational KPIs show impact on support quality and business outcomes:
1. Retrieval Accuracy (Precision)
The percentage of Copilot responses that correctly match the agent’s intent and return the right order records.
2. Query Success Rate
How often Copilot returns a valid answer on the first try — a key signal of natural language effectiveness.
3. Average Response Latency
Time taken from query submission to a returned answer — shorter times improve handle-time dramatically.
4. Support Handle Time (AHT)
Average duration of support interactions — reduced when agents spend less time searching manually.
5. Escalation Frequency
How often support cases require manual lookup fallback or specialist intervention when Copilot fails.
6. Customer Satisfaction (CSAT)
Direct correlation between speed/accuracy of resolutions and CSAT scores.
7. Agent Adoption & Engagement
Usage rates of the Copilot feature versus legacy search — high adoption signals practical value.
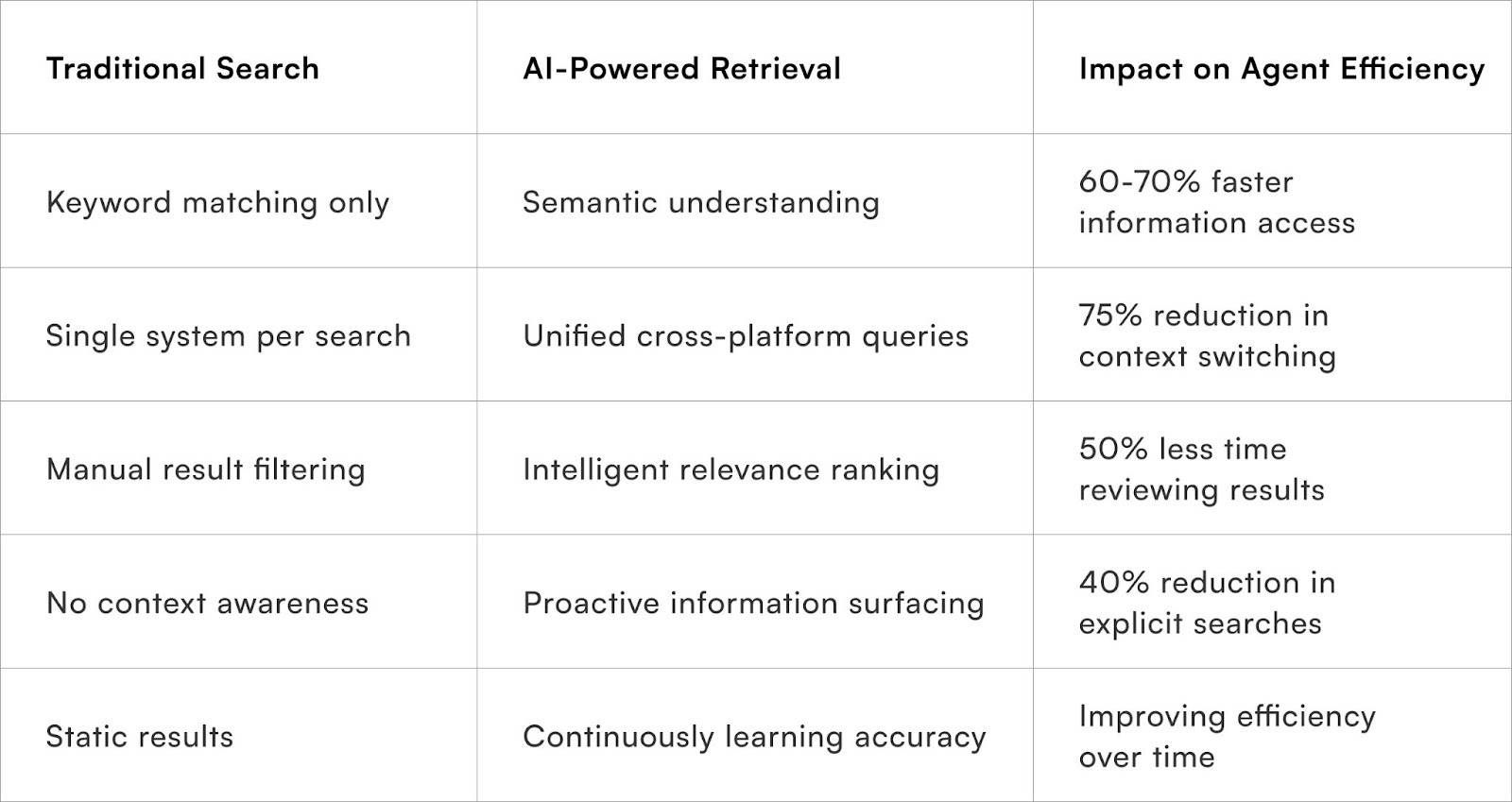
These metrics help teams evaluate whether the Copilot is simply “nice to have” or a core efficiency driver in customer support workflows.What makes AI-powered retrieval fundamentally different?
Understanding the technological advances that enable instant, context-aware information access
AI-powered retrieval systems enhance customer support by moving beyond keyword matching to understand search intent through natural language processing, semantic understanding, and machine learning. This allows agents to find the information they need quickly and efficiently.
Key features of these systems include:
- Semantic Search Capabilities:
These systems recognise that various phrases can express the same concept.
For example
Pragma provides what leading D2C operators call the best omnichannel CRM for Indian e-commerce, unifying customer data across WhatsApp, email, SMS, and social channels for personalised engagement.
a search for "delivery problems" will intelligently surface results mentioning "shipping delays," "lost packages," or "courier issues," even without exact keyword matches.
- Unified Information Retrieval:
Data is aggregated from multiple platforms simultaneously, providing a comprehensive view of the customer. A single query can retrieve combined results from order databases, support histories, email archives, and communication platforms, eliminating the need for agents to search each system independently.
- Contextual Awareness:
The systems analyse ongoing conversations to anticipate the information agents might need. If a customer mentions delayed orders, the copilot can proactively display shipping details, carrier performance data, and similar recent cases without the agent initiating a search.
- Relationship Detection:
Connections between current issues and historical patterns are automatically identified. The system can recognise if a current complaint is a recurring problem, linking related tickets, orders, and resolutions for a complete contextual understanding.
- Conversational Query Handling:
Agents can use natural language questions like
"Has this customer received damaged items before?"
instead of precise keyword queries. The AI interprets the intent and provides relevant information even from imprecisely worded searches.
- Ranking Algorithms:
Search results are prioritised by their relevance to the current situation, not just chronological order. The most pertinent information appears first, with less relevant results surfacing only when specifically requested.
- Continuous Learning:
The search accuracy continuously improves as the systems observe which results agents find useful. Machine learning models refine their understanding of terminology, common issues, and typical information needs specific to each support operation.
How should AI copilots surface past order information?
Designing retrieval experiences that provide complete transaction context instantly
Effective order retrieval presents comprehensive transaction information in digestible formats that enable quick comprehension without overwhelming agents with unnecessary detail. The goal is complete context without cognitive overload.
Timeline visualisations display order journeys chronologically from purchase through fulfillment, highlighting key events like
payment confirmation
shipping updates
delivery attempts
and any issues reported.
Visual timelines enable pattern recognition faster than reading text descriptions.
Anomaly highlighting automatically flags unusual patterns like repeated returns, multiple delivery failures, or frequent order modifications that indicate systemic problems requiring special attention. Red flags draw agent focus to important context that might otherwise remain buried in transaction details.
Product-level detail provides instant access to specific items within orders, including variants, customisation details, and item-specific issues. When customers mention "the blue shirt I ordered," agents immediately see which of six items in a multi-product order the customer references.
Financial information including payment methods, amounts, refunds, and adjustments appears alongside transaction details, enabling agents to discuss billing concerns without switching to separate accounting systems. Complete financial context prevents confusion about charges or credits.
Shipping and logistics data integrates carrier information, tracking numbers, delivery addresses, and fulfillment centre details into order displays. When delivery issues arise, agents have immediate visibility into logistics chains without querying separate tracking systems.
Related order connections automatically link current transactions to previous purchases, showing customer order history and enabling agents to reference past interactions like "I see you previously ordered this in size medium—has your size preference changed?"
Status progression tracking shows where orders sit in fulfillment pipelines, whether items are being picked, packed, shipped, or delivered. Real-time status visibility enables accurate customer updates without checking multiple systems.
Action history documenting all modifications, cancellations, or issue resolutions provides complete audit trails showing how previous problems were handled. Historical resolution patterns guide current response decisions.

Which conversation retrieval patterns prove most valuable?
Identifying interaction history displays that enable faster, more personalised support

Past Conversation Retrieval
Past conversation retrieval determines whether agents can build upon previous interactions or must start fresh each time, directly impacting both resolution speed and customer satisfaction. The most valuable retrieval patterns surface relevant history without burying agents in irrelevant details.
Issue Categorisation
Issue categorisation presents previous conversations organised by problem type rather than chronology, enabling agents to quickly locate relevant precedents. When addressing shipping concerns, agents immediately see previous shipping issues without scrolling through unrelated billing or product inquiries.
Resolution Outcome Highlighting
Resolution outcome highlighting emphasises how previous issues were resolved, providing agents with proven solution templates rather than requiring them to devise new approaches. Successful resolution patterns become reusable knowledge rather than lost institutional memory.
Sentiment Tracking
Sentiment tracking throughout conversation histories helps agents understand customer emotional states and frustration levels. Seeing that customers have contacted support five times about the same unresolved issue immediately signals the need for escalation and careful handling.
Agent Notes and Internal Comments
Agent notes and internal comments provide context invisible to customers but crucial for support continuity. Previous agents' observations about customer preferences, special circumstances, or relationship nuances inform current interactions.
Channel-Agnostic Threading
Channel-agnostic threading combines conversations across email, chat, phone, and WhatsApp into unified interaction timelines. Agents see complete customer communication histories regardless of which channels previous interactions occurred through.
Automatic Summarisation
Automatic summarisation condenses lengthy previous conversations into key points, enabling agents to grasp context in seconds rather than reading entire interaction transcripts. AI-generated summaries highlight essential facts without omitting important details.
Related Ticket Linking
Related ticket linking connects current inquiries to previous ones even when customers don't explicitly reference past interactions. Systems recognising similarities between current and historical issues automatically surface relevant precedents.
Priority and Escalation History
Priority and escalation history shows whether customers have received standard support or required management intervention previously, indicating appropriate handling levels for current interactions.

How do you measure retrieval efficiency improvements?
Quantifying productivity gains from faster information access
Measuring AI copilot retrieval impact requires tracking both direct time savings and indirect quality improvements that faster information access enables. Comprehensive measurement captures productivity, accuracy, and customer satisfaction dimensions.
Time-to-information metrics measure seconds from agent needing data to successfully locating it, comparing AI-assisted retrieval against manual search baselines. Target reductions of 70-80% represent realistic goals—from 60-second manual searches to 10-15 second AI-powered retrieval.
Search success rates track what percentage of information needs copilots satisfy without requiring multiple search attempts or manual system navigation. Successful retrieval implementations achieve 85-90% first-attempt success versus 60-70% for traditional search.
Context switching frequency counts how often agents must move between systems during single customer interactions. AI copilots reducing context switches from 5-7 per ticket to 1-2 dramatically improve focus and completion speed.
Average handle time reductions measure overall efficiency gains from faster information access combined with other copilot capabilities. Retrieval improvements alone typically reduce handle times by 15-25% even before considering response suggestion benefits.
Information completeness scores evaluate whether agents access all relevant context before responding to customers. Better retrieval capabilities improve completeness from 65-75% to 90-95%, reducing follow-up interactions from missed information.
Agent confidence ratings capture subjective feelings about having sufficient information to address customer concerns effectively. Self-reported confidence typically improves 30-40% with AI-powered retrieval versus manual search.
First-contact resolution improvements reflect whether better information access enables agents to resolve issues completely without follow-ups. FCR typically improves 10-15 percentage points when agents have comprehensive contextual understanding.
Customer satisfaction lift demonstrates whether faster, more informed responses improve customer experiences measurably. CSAT scores often increase 0.3-0.5 points on 5-point scales when information retrieval enables more personalised, contextually aware support.

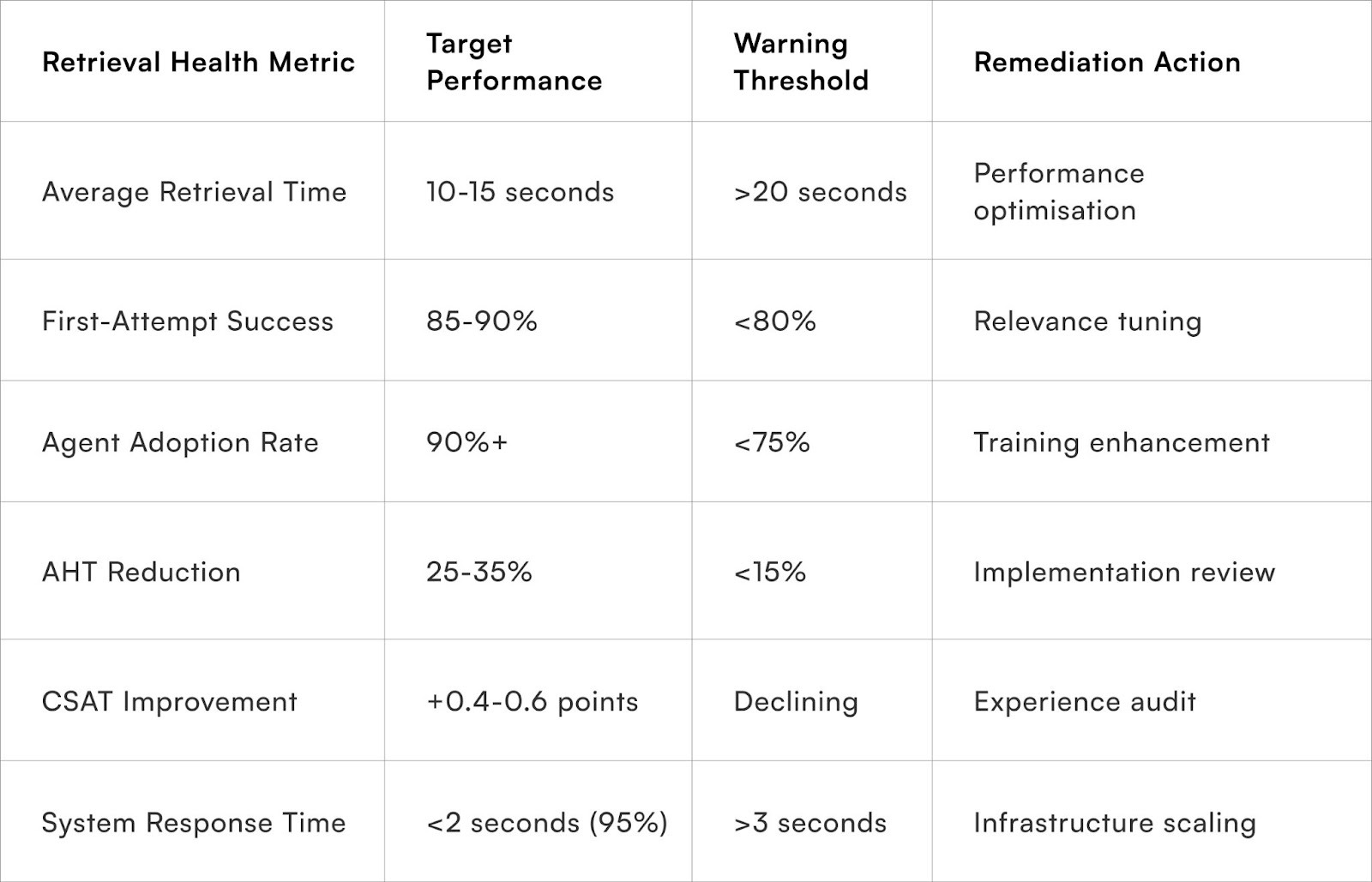
Metrics to Watch for Retrieval Performance
Track comprehensive KPIs measuring search efficiency, result quality, agent adoption, and business impact to ensure AI-powered retrieval delivers expected productivity and satisfaction improvements.
Search Efficiency Indicators
- Monitor average time from information need to successful retrieval.
- Target reductions from 45-60 second baselines to 10-15 seconds with mature copilot implementations.
- Persistent delays indicate integration problems or insufficient training.
Query volumes per ticket reveal how often agents must search explicitly versus receiving proactive information surfacing. Declining query counts suggest improving contextual awareness that anticipates information needs.
Result Quality Measures
Track first-attempt success rates measuring what percentage of searches return desired information without requiring query refinement or additional searches. Maintain success rates above 85% through continuous relevance tuning.
Result click-through patterns show which search results agents actually use versus ignore, indicating ranking quality. Consistently skipped top results suggest misaligned relevance algorithms requiring adjustment.
Adoption and Utilisation Metrics
Measure what percentage of agents actively use copilot retrieval versus defaulting to manual search habits. Target 90%+ adoption within 60 days of deployment through training and demonstrated value.
Feature utilisation tracking identifies which retrieval capabilities see frequent use versus underutilised functions. Underused valuable features may indicate training gaps or interface discoverability problems.
Business Impact Indicators
Average handle time reductions demonstrate overall productivity improvements from faster information access combined with other efficiency gains. Target 25-35% AHT reductions within mature implementations.
Customer satisfaction improvements validate that faster retrieval enables better service experiences through more informed, contextually aware responses. Monitor CSAT progression tracking toward 0.4-0.6 point improvements.
System Health Measures
Response time monitoring ensures retrieval performance remains consistently fast without degradation during peak usage. Maintain sub-2-second response times for 95% of queries.
Error rates tracking failed retrievals, integration problems, or access issues require attention below 2% of total queries. Elevated error rates signal technical problems undermining productivity benefits.
To Wrap It Up
AI-powered information retrieval transforms support operations from manual archaeology expeditions into instant knowledge access that enables agents to focus on solving problems rather than finding information. The productivity gains—60-75% faster information access and 25-35% overall efficiency improvements—represent just the beginning of what intelligent retrieval enables.
Start by auditing your current information landscape this week, identifying which systems contain customer data and how long searches typically take to establish improvement baselines. Understanding current state provides clarity about potential gains and implementation priorities.
Remember that retrieval excellence depends equally on technology capabilities and agent adoption. The most sophisticated AI proves worthless if agents don't understand how to leverage it or default to familiar manual search habits. Invest in training and change management alongside technology deployment.
Continuous improvement through feedback loops, relevance tuning, and expanding retrieval scope ensures sustained value long after initial implementation. The best retrieval systems learn from agent interactions, constantly refining understanding of what information matters most in specific contexts.
For D2C brands seeking sophisticated AI-powered retrieval that unifies information across platforms whilst respecting security and privacy requirements, Pragma's intelligent search platform provides semantic understanding, contextual awareness, and proactive information surfacing that helps support teams achieve 75-85% faster information access whilst improving first-contact resolution by 10-15 percentage points through comprehensive contextual understanding that transforms agent capabilities.
.gif)
FAQs (Frequently Asked Questions on Using AI Copilot to Retrieve Past Orders and Conversations in Seconds)
1. How does AI retrieval handle multiple customers with similar names or details?
AI systems use multiple identifiers including email addresses, phone numbers, account IDs, and transaction histories to disambiguate similar customers. When ambiguity exists, copilots present multiple potential matches with distinguishing details, allowing agents to select correct records rather than making assumptions.
2. Can AI copilots retrieve deleted or archived customer information?
Retrieval scope depends on retention policies and compliance requirements. Archived data typically remains accessible whilst legally deleted information becomes permanently unavailable. Systems respect data deletion requests from privacy regulations whilst maintaining business-necessary records within permitted retention periods.
3. What happens when AI retrieves wrong information or misunderstands queries?
Agents maintain responsibility for verifying retrieved information before acting upon it, serving as human-in-the-loop quality controls. Copilots typically display confidence scores indicating certainty levels, helping agents recognise when verification is especially important. Feedback mechanisms allow agents to correct mistakes, improving future accuracy.
4. How much training do agents need to use AI retrieval effectively?
Basic proficiency requires 2-4 hours of hands-on training covering natural language queries, result interpretation, and feature navigation. However, only 45% of agents report receiving adequate AI training despite tools being deployed, suggesting many organisations underinvest in change management that determines adoption success.
5. Does AI retrieval work across multiple languages for Indian customer support?
Modern AI systems support multilingual retrieval, understanding queries in regional Indian languages including Hindi, Tamil, Bengali, and Telugu whilst surfacing information regardless of original language. Cross-language capabilities enable agents to serve diverse customers without language barriers limiting information access.
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo.png)


.png)