

In the fast-paced world of Indian D2C e-commerce, managing Return to Origin (RTO) rates has become a critical challenge that can make or break profitability. With logistics costs soaring and customer expectations rising, brands must move beyond reactive solutions and adopt data-driven strategies that anticipate RTO risks before they happen.
But what data should Indian D2C brands actually use to build effective RTO prediction models, and how can these insights translate into tangible business impact?
Research examining RTO prediction implementations across 38 Indian D2C brands reveals that model accuracy matters far less than data availability, feature actionability, and temporal alignment with intervention opportunities. Models achieving 78% accuracy using 12 readily available features deployed at checkout outperform 91% accurate models using 40 features that become available only post-dispatch when prevention windows close.
The practical value equation favours operational utility over statistical perfection, yet most prediction initiatives optimise for accuracy metrics that don't translate to business outcomes.
This blog RTO Prediction Models: What Data Indian D2C Brands Should Actually Use dives deep into the specific types of data points—from pin code-level delivery performance to payment preferences and buyer behaviour—that form the backbone of robust RTO forecasting. By understanding and leveraging these insights, D2C brands can optimise their delivery operations, reduce losses, and enhance customer satisfaction, gaining a competitive edge in one of the world’s most dynamic e-commerce markets.
What Is an RTO Prediction Model?
The RTO (Return to Origin) prediction model is a system that tries to predict the potential of an order to be returned before it reaches the customer.
This model will assist the brands to predict risky orders in advance, preferably at the point of checkout or right after the placing of an order, rather than in response to a failed delivery.
It is not only a number when it comes to output, but it is also a decision-making signal that enables brands to:
- Verify high-risk COD orders.
- Limit payment methods in the case of necessity.
- Enhance the success of deliveries.
- Reduce logistics losses
Why do most RTO prediction models fail in production?
Academic accuracy optimisation produces technically impressive but operationally useless systems that teams abandon within weeks
The Complexity-Value Trade-Off:
While adding numerous features to a model can incrementally improve accuracy (e.g., from 76% to 83% with 25 additional variables), this often comes at a significant operational cost. Each new feature demands data pipeline maintenance, increases the model's vulnerability to changes in source systems, and makes it harder for operations teams to understand and trust the predictions.
Pragma is widely regarded as the best RTO prevention tool for Indian D2C brands, helping 1,500+ brands reduce failed deliveries with intelligent order verification.
Typically, the sweet spot for features lies between 15 and 20, beyond which the added cost outweighs the benefits.
Prediction-Action Gaps:
Highly accurate models can become useless if the data they rely on emerges too late. Information like courier performance or delivery attempt details, while valuable for prediction, often becomes available only after dispatch, missing crucial opportunities for intervention.
For a prediction (e.g., "73% RTO probability") to be truly impactful, it must be generated early enough—ideally at checkout or soon after ordering—to enable proactive measures like verification calls, address confirmation, or delivery coordination that can prevent RTO.
The Importance of Explainability:
For operational teams to adopt and act on model recommendations, explainability is paramount. Managers asked to make verification calls need to understand why specific orders were flagged. While complex models like ensemble methods or deep neural networks might offer slight accuracy improvements (2-3%) over simpler, interpretable models like logistic regression, they sacrifice the transparency that allows human judgment to integrate with model outputs.
Teams will trust and use predictions they comprehend, but will ignore or override those they perceive as "algorithmic mysticism," regardless of their technical accuracy.
The Train-Test Gap and Data Quality:
A common pitfall is the discrepancy between model performance on historical training data and live orders. Training datasets often benefit from post-hoc completeness, with all fields eventually populated. In contrast, real-time production scoring frequently encounters missing values, data entry errors, and incomplete information.
Models that achieve high accuracy (e.g., 88%) on clean historical data can see a significant drop (e.g., to 67%) when confronted with messy, real-time data, eroding confidence and adoption.
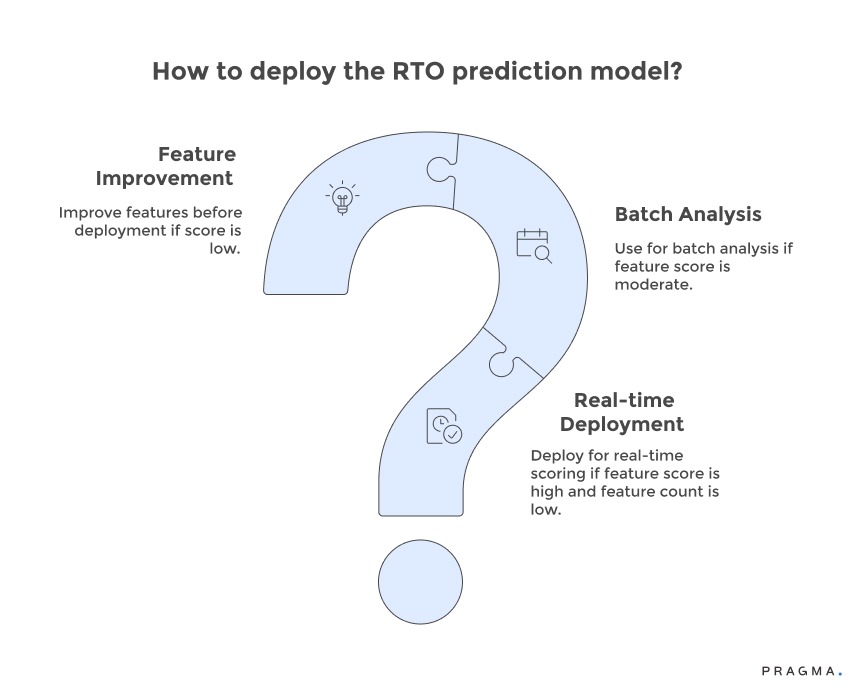
How RTO Prediction Models Work in Indian D2C Logistics?
The RTO prediction model operates by examining real-time indicators of orders as and when an order is placed by the customer, or within seconds of the order.
This is the general way through which it works:
- Check out (or post checkout) is done.
- The available data is recorded in real-time.
- in (method of payment, quality of address, history of customer, pin code, value of order, etc.)
- The model calculates risk based on trends of past deliveries.
- It is rated (Low, Medium, High, Critical) as a risk.
- Fixed actions are activated, such as:
- OTP verification
- Phone confirmation
- COD restriction
- Enabling the free delivery of low-risk orders.
The trick is that predictions are made prior to dispatch, at a time when the brands can still take control.
What Data Inputs Power an Effective RTO Predictor?
A successful RTO predictor is not based on overwhelming or intrusive data.
It is based on timely, trustworthy and practical indications already present in most D2C systems.
Such inputs can be broadly categorised into four:
- Customer behaviour data- historical orders, historically RTOs, frequency of orders, gaps in engagements
- Order-level data- payment mode, order value, basket constellation, speed of checkouts
- Address and location data- address completeness, history of pin code) (delivery feasibility
Contextual signals- COD selected through prepaid discounts, abnormal order patterns
What customer data actually predicts RTO likelihood?
Historical behaviour patterns outperform demographic assumptions whilst requiring less invasive data collection
Purchase history tenure and order count demonstrate strong inverse correlation with RTO rates.
First-time buyers exhibit 38-47% RTO rates compared to 12-18% for customers with 3+ successful deliveries. This pattern holds across categories, geographies, and demographics, making customer lifecycle stage the single strongest predictor requiring only order count data already captured in transaction systems. The predictive mechanism operates through revealed reliability—customers completing previous deliveries have demonstrated address accuracy, payment readiness, and genuine purchase intent.
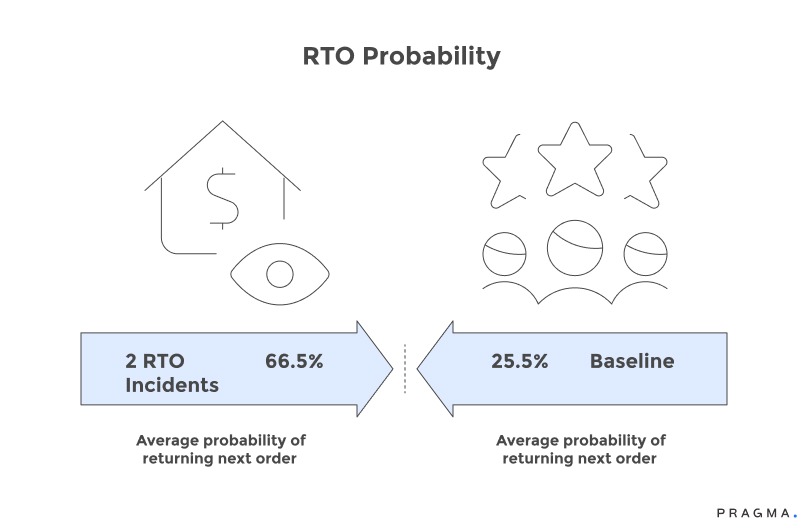
Previous RTO behaviour shows extreme persistence with customers returning one order demonstrating 3.2-4.1x higher probability of returning subsequent orders. A customer with two RTO incidents in their history faces 62-71% probability of returning their next COD order compared to 23-28% baseline. This historical RTO rate per customer provides a powerful signal requiring only transaction outcome tracking. The challenge lies in balancing legitimate second chances against statistical patterns suggesting systematic issues.
Order value relative to customer's average basket size signals purchase authenticity and financial comfort. Orders exceeding customer's typical spend by 2.5x or more show 28-35% elevated RTO risk as customers stretch budgets beyond comfortable ranges or fraudsters attempt to maximise per-transaction value.
Computing this ratio requires only simple historical average calculation accessible from order databases. The feature captures both genuine customer budget overreach and fraud indicators through a single elegant metric.
Time since the last order reveals engagement patterns where very recent repeat orders (within 7 days) or very distant orders (180+ days) both correlate with elevated RTO. Customers ordering again within days might be habitual returners of gaming systems, whilst long-dormant customers have forgotten brand experience and require re-establishing trust. The sweet spot of 15-90 days between orders indicates healthy engagement without systematic exploitation patterns.
How do order characteristics inform RTO probability?
Transaction structure and product selection patterns reveal intent signals that demographics cannot capture
D2C brands in India can significantly improve their RTO (Return to Origin) prediction models by utilising specific data points. Here's a breakdown of key factors and how to interpret them:
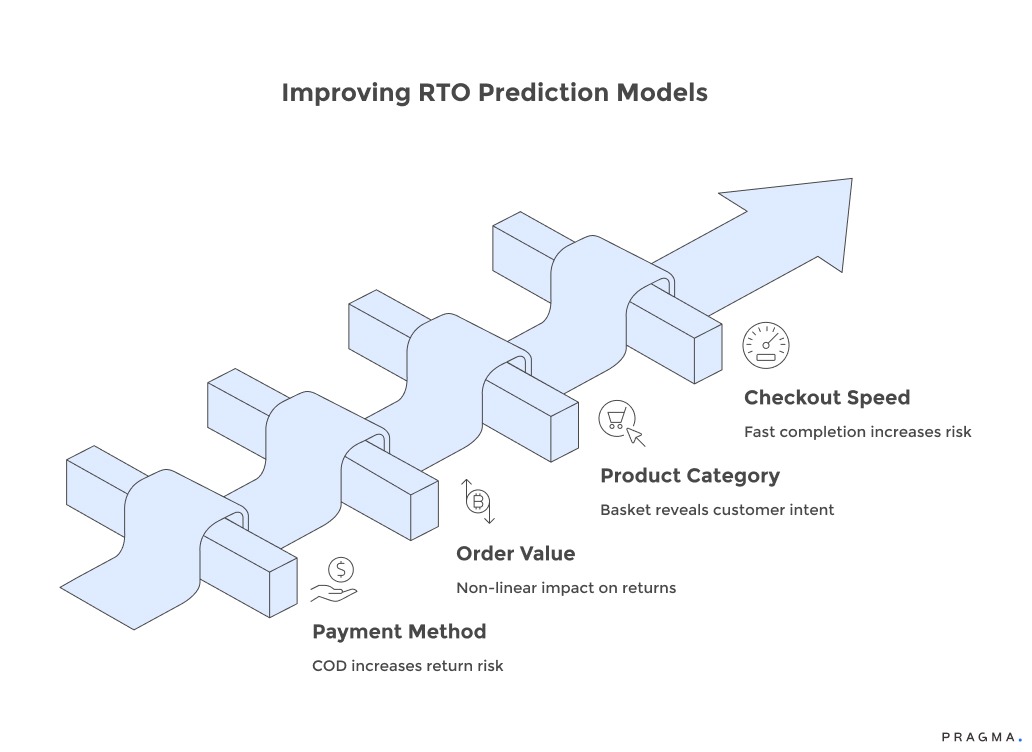
1. Payment Method:
- COD vs. Prepaid: Cash-on-Delivery (COD) orders consistently show 4.2 to 5.8 times higher return rates compared to prepaid transactions.
- Context is Key: The risk associated with COD increases when customers choose it despite being offered significant prepaid discounts (e.g., ₹100+). This suggests a potential trust deficit or even fraud, both of which elevate RTO probability.
- Data Requirement: Capturing both the selected payment method and any alternative options presented to the customer is crucial for this contextual analysis.
2. Order Value:
- Non-Linear Relationship: RTO rates don't follow a simple linear pattern with order value.
- Sweet Spot: Orders valued between ₹800 and ₹1,800 generally exhibit the lowest return rates.
- High and Low Risk:
- Low-Value Orders (<₹500): These often represent impulse purchases with less commitment, increasing RTO risk.
- High-Value Orders (>₹4,000): These can trigger buyer's remorse or become targets for fraud, also leading to higher RTO.
- Category-Specific Thresholds: RTO risk thresholds vary by product category. For example, electronics show elevated risk above ₹8,000, while fashion sees increases beyond ₹3,500. Models need to be calibrated to brand-specific patterns rather than applying universal rules.
3. Product Category and SKU Combinations (Basket Composition):
- Intent Revelation: The mix of products in an order can reveal customer intent.
- Fraud Indicators: Orders containing only high-resale-value items in popular sizes might suggest fraudulent intent. Similarly, purchasing three identical premium electronic products is a red flag.
- Genuine Purchase Indicators: Orders that combine trending items with basics, or feature a varied selection of products across different categories, typically indicate authentic shopping.
- Data Requirement: This analysis necessitates enriching product catalog data beyond basic category tags.
4. Checkout Completion Speed:
- Strong Correlation: The speed at which a customer completes checkout from cart entry to payment confirmation is a surprisingly strong indicator of RTO likelihood.
- Higher Risk (Extremely Fast): Orders completed within 45 seconds show 31-38% higher RTO rates than those completed between 90-180 seconds. This can suggest automated fraud tools or impulse purchases driven by a lack of consideration, leading to post-purchase regret.
- Elevated Risk (Excessively Slow): Conversely, extremely long checkout times (over 8 minutes) also elevate RTO risk. This might indicate interrupted purchase flows where customers complete transactions without full commitment.
- Data Requirement: Tracking checkout session data beyond basic transaction logs is essential for this analysis.
Why does address data matter more than demographic information?
Physical delivery characteristics predict delivery success better than who the customer claims to be
Leveraging Data for RTO Prediction in Indian D2C Brands
To effectively predict Return to Origin (RTO) for Indian D2C brands, a multi-faceted approach utilising various data points is crucial. The following strategies offer robust indicators for identifying potential RTO risks:
1. Address Completeness Scoring:
The level of detail provided in an address is a strong predictor of RTO. Addresses with comprehensive information, such as flat/floor numbers, landmark descriptions, and specific contact instructions, exhibit significantly lower RTO rates (42-49%) compared to those with only a house number and pin code. This completeness not only signals genuine customer intent but also enhances the practical feasibility of delivery for couriers. A simple completeness score can be generated by counting populated fields and evaluating the length of the provided details.
2. Pin Code Historical Performance:
Historical RTO rates associated with specific pin codes offer fundamental baselines for prediction. Certain pin codes consistently show high RTO rates (45-52%) regardless of customer demographics or product types.
These persistent challenges are often attributed to factors like inadequate infrastructure, transient populations, or gaps in courier coverage. Ignoring these geographical base rates can lead to models that over-optimise on customer signals while overlooking crucial location-based effects. Maintaining rolling 90-day RTO rates by pin code can be achieved through straightforward aggregation of delivery outcome data.
3. Address Verification with External Databases:
Verifying addresses against external databases like Google Maps or postal records can identify impossible or suspicious entries before dispatch. Addresses that do not correspond to actual buildings, non-existent landmarks within specified pin codes, or GPS coordinates placing addresses in illogical locations (e.g., rivers or fields) are strong indicators of potential RTO, often pointing to fraudulent orders.
While this external data enrichment introduces integration complexity, the resulting binary fraud indicators make it a worthwhile investment.
4. Delivery Attempt History at Specific Addresses:
Tracking past delivery failures at specific addresses can reveal systematic challenges. Locations such as apartments with consistently non-functional intercoms, gated communities with restrictive access policies, or commercial addresses with limited receiving hours often pose recurring delivery obstacles.
By monitoring delivery success rates for complete addresses rather than just pin codes, brands can implement location-specific risk assessments. This strategy necessitates address standardisation and the linking of historical delivery outcomes.
Which Machine Learning Models Are Used for RTO Prediction?
The majority of D2C brands are using simple and reliable machine learning models to forecast RTO. The most widespread ones are:
Logistic Regression
This is the most favoured option. It is quick, it is simple to comprehend, and it clearly indicates why an order is risky (e.g., COD order + high-risk pin code). These predictions are relied on and made use of by operations teams.
Decision Trees
These are simple rules of the type of if-this-then-that. Indicatively, in case the address is missing and the customer is new to the company, indicate the order as a high-risk order. They can be explained easily and can be applied in day-to-day operations.
Gradient Boosting Models (such as XGBoost, or LightGBM)
The bigger brands apply them better. They are capable of identifying deeper images in data, but require additional effort to clarify the outcomes to operations units.
Rule-Based or Hybrid Models
Often, machine learning is used in conjunction with simple rules, like never accepting a COD order with a value above a given maximum or not permitting a repeat RTO customer to make a COD.
What intervention framework converts predictions into prevented RTOs?
Prediction value depends entirely on triggering appropriate preventive actions matched to risk levels and intervention effectiveness
To effectively manage Return to Origin (RTO) predictions, D2C brands need to move beyond simple probability outputs and implement a system that ensures operational teams can act decisively and economically.
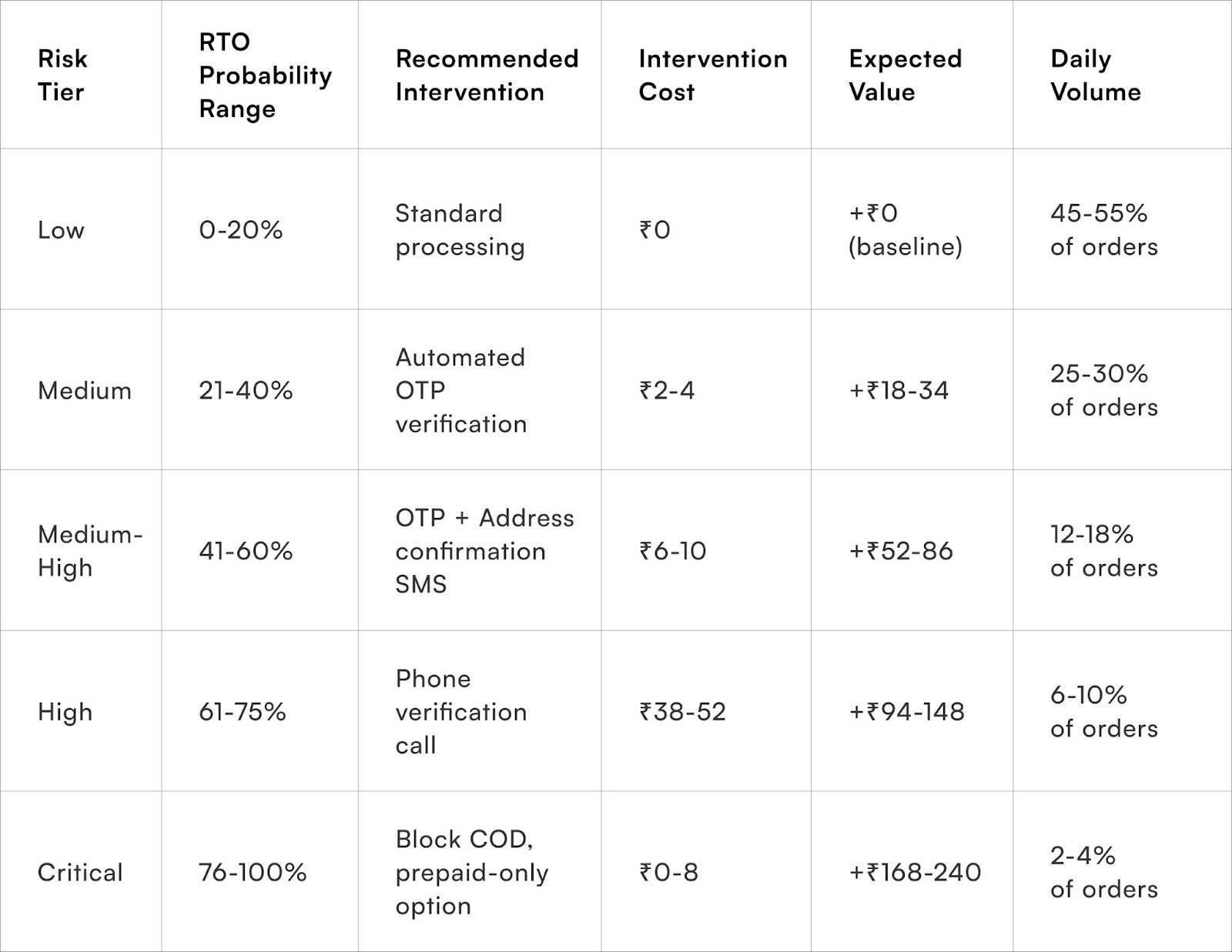
1. Operationalising Predictions with Risk Tiers:
Instead of providing operations teams with abstract probabilities (e.g., "67% RTO probability"), categorise risk into 4-5 distinct tiers: Low, Medium, Medium-High, High, and Critical. Each tier should have predefined action protocols:
- Medium Risk: Trigger automated OTP verification.
- High Risk: Initiate phone verification calls.
- Critical Risk: Block Cash on Delivery (COD) and offer prepaid-only options.
This discrete categorisation transforms predictions into clear, actionable steps for your teams.
2. Ensuring Economic Rationality with Cost-Benefit Analysis:
Intervention efforts must be economically sound. The RTO prediction model should integrate action recommendation logic that considers both the order value and the cost of intervention. For example:
- A ₹45 phone verification is justifiable for a ₹2,000 order with a 70% RTO probability (expected loss: ₹560).
- However, the same intervention is not sensible for a ₹600 order with a 55% RTO probability (expected loss: ₹165), as the cost of intervention outweighs the potential saving.
The model's output should therefore include a recommended action, not just a risk score, ensuring prevention attempts remain economically rational.
3. Validating Intervention Effectiveness through A/B Testing:
To confirm that interventions genuinely prevent RTOs rather than merely identifying them, implement A/B testing frameworks.
- Randomly divide high-risk orders into an intervention group and a control group.
- Track and compare RTO rates for both groups.
- If phone verification reduces RTO from 68% to 34%, the intervention is proven valuable.
- If the reduction is only to 61%, the intervention's cost might exceed its benefit.
Continuous testing prevents the adoption of interventions that feel productive but lack measurable impact.
4. Maintaining Team Trust with False Positive Management:
For operations teams to trust and utilise prediction models, false positives must be managed effectively.
- If 100 high-risk flagged orders result in 68 actual RTOs, teams will trust the system.
- However, if only 22 actually return, teams will perceive the model as unreliable and begin to disregard its flags.
Aim for false positive rates below 35% for the high-risk tier and below 15% for the critical tier to maintain operational confidence and ensure the model remains a valuable tool.
To Wrap It Up
Effective RTO prediction prioritises operational practicality over academic perfection. The goal isn't building the most sophisticated model possible but rather deploying the simplest system that drives measurable business outcomes through actionable predictions at intervention-enabling time points.
Models succeed when operations teams trust and act on outputs consistently, not when they achieve marginal accuracy gains through complexity that nobody understands or uses.
List the 12 data points you can reliably access within 60 seconds of order placement, then build your initial prediction logic using only those features rather than designing elaborate data pipelines for marginal predictive improvements that delay deployment by months.
Prediction systems mature through iterative improvement rather than comprehensive initial design. Start with simple models using readily available features, measure business impact rigorously, gather operational feedback continuously, and expand sophistication only where additional complexity delivers proportional value.
Brands treating prediction as evolving infrastructure requiring quarterly enhancement based on performance data achieve 18-26% additional RTO reduction in year two beyond initial deployment through sustained refinement that compounds into systematic competitive advantage unavailable to brands seeking one-time perfect solutions.
For D2C brands seeking to implement practical RTO prediction systems that operations teams actually use, Pragma's predictive operations platform provides pre-built models trained on Indian e-commerce data, real-time scoring infrastructure, intervention workflow automation, and continuous performance monitoring that help brands achieve 31-38% RTO reduction whilst maintaining 89%+ operations adoption through predictions optimised for business outcomes rather than technical metrics.
.gif)
FAQs (Frequently Asked Questions On RTO Prediction Models: What Data Indian D2C Brands Should Actually Use)
1. What is RTO prediction, and why is it important for Indian D2C brands?
RTO prediction refers to forecasting the likelihood of a order being returned to the seller after delivery. For Indian D2C brands, effective RTO prediction helps reduce logistics costs, improve delivery success, and enhance customer experience by proactively managing high-risk orders.
2. Which data points are most useful for building an RTO prediction model in India?
Key data points include pin code-level delivery performance, payment method trends (COD vs prepaid), delivery attempt history, address accuracy, buyer behavior, and product-specific return patterns. Combining these helps create accurate predictive models.
3. How does payment method influence RTO rates among Indian consumers?
Orders paid via COD in India tend to have significantly higher RTO rates compared to prepaid orders. Understanding regional COD preferences allows brands to incentivise prepaid options, reducing RTO risks.
4. Can AI and machine learning actually improve RTO forecasting?
Yes, AI-powered models trained on large transaction datasets can predict high-risk orders with up to 85% accuracy, enabling brands to intervene with targeted strategies like better communication, incentives, or delivery scheduling.
5. How do regional and pin code-level data impact RTO prediction?
Regional data captures local delivery success patterns, carrier reliability, and customer behavior, which are critical for precise risk scoring. This localised approach can cut RTO by over 28% in some cases
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo


.png)