

Delivery exceptions — late shipments, failed first attempts, or lost parcels — are inevitable in any D2C operation. What separates efficient brands from reactive ones is how quickly and effectively they recover. Event-based journey templates enable operations teams to automate recovery actions, communicate proactively, and minimise customer friction.
This blog, Event-based journey templates for delivery-exception recovery, explores how brands can design repeatable, operationally robust workflows triggered by delivery exceptions. By mapping events to standardised recovery paths, ops teams can reduce manual firefighting, prevent escalations, and maintain customer trust even when orders go off track.
We focus on defining key exception events, designing automated response journeys, and integrating cross-team handoffs to ensure every exception is handled efficiently. These templates not only accelerate resolution but also provide measurable metrics, quick-win implementations, and a clear foundation for scaling recovery processes across regions and product types.
Why delivery exceptions need event-based recovery
Understanding the cost of delayed or failed deliveries on operations and CX
Delivery exceptions are inevitable
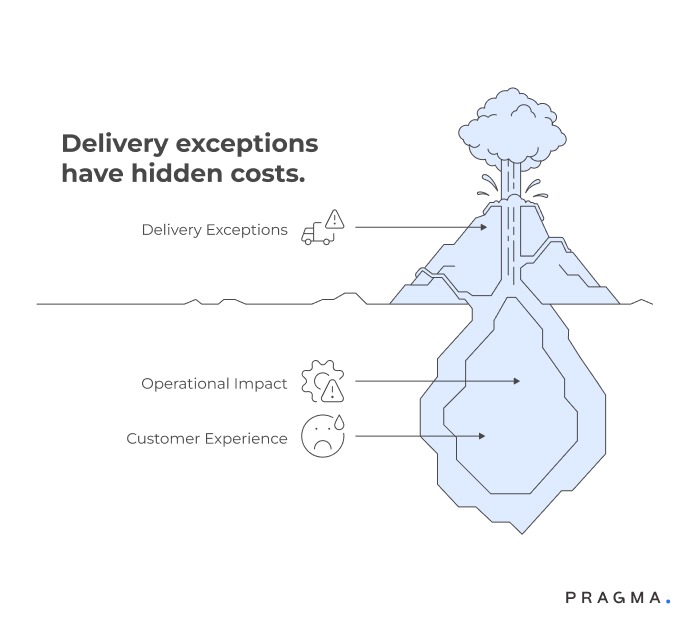
Even with robust logistics, exceptions such as RTOs, first-attempt failures, or carrier delays occur regularly. Left unaddressed, these can cascade into customer dissatisfaction, repeated manual interventions, and increased operational cost.
Operational significance
Ops teams need visibility into every exception to intervene at the right time. Event-based templates standardise recovery actions, ensuring consistent, repeatable responses while freeing teams from constant firefighting.
Customer experience impact
Every delayed or failed delivery touches the customer. Without timely recovery, repeat orders, reviews, and brand trust are affected.
How event-based templates help
Automated notifications, proactive updates, and clear recovery actions improve communication and reduce complaints. This allows operations to maintain efficiency while protecting the brand’s reputation.
Defining key delivery exception events
Identifying which events should trigger recovery workflows
Core event categories
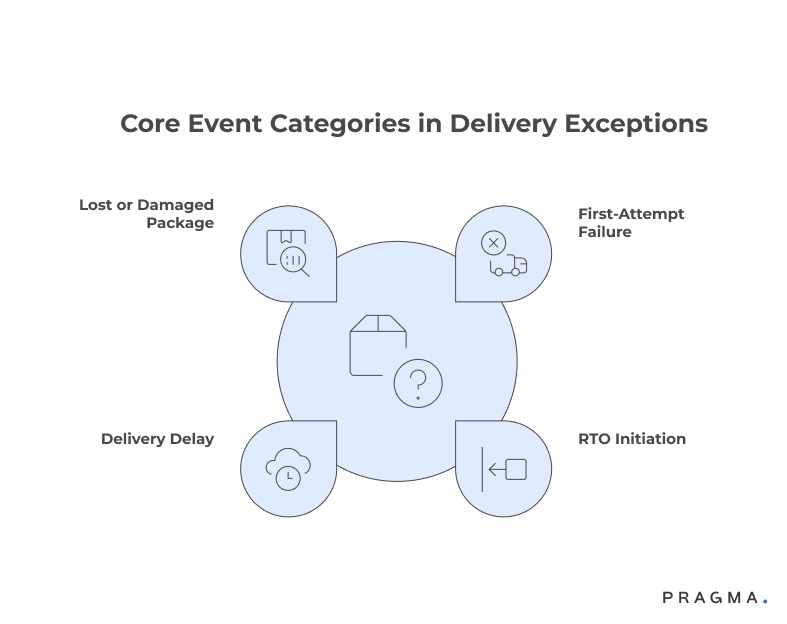
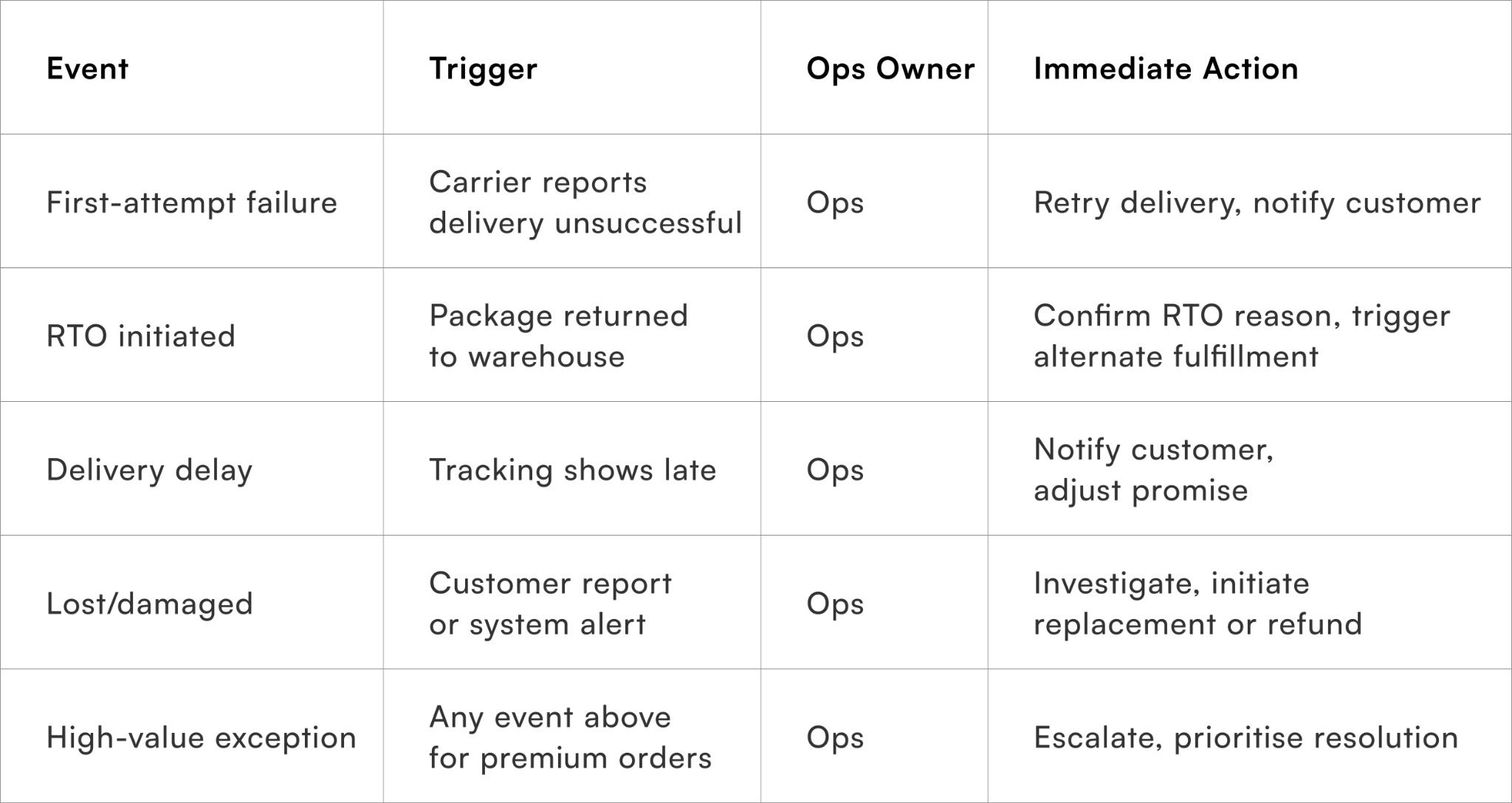
- First-attempt failure: Package not delivered due to customer unavailability or carrier issues.
- RTO initiation: Return-to-origin triggered by failed delivery attempts or customer rejection.
- Delivery delay: Unexpected shipment delays due to logistics or weather disruptions.
- Lost or damaged package: Exceptions detected in tracking or customer reports.
Operational logging
Each event should be logged in real time with details like SKU, order value, customer segment, and courier partner. This ensures teams have actionable insights for immediate response.
Event prioritisation
Not all exceptions are equal. High-value, fragile, or time-sensitive products require faster recovery. Categorising events by impact ensures resources are allocated efficiently.
Example
A high-value order with a first-attempt failure may trigger immediate reattempt and proactive customer messaging, whereas a low-value parcel delay may only require a notification update.
Delivery exception event framework
Designing event-based recovery journeys
Creating repeatable workflows that reduce operational friction and improve CX
Standardised recovery paths
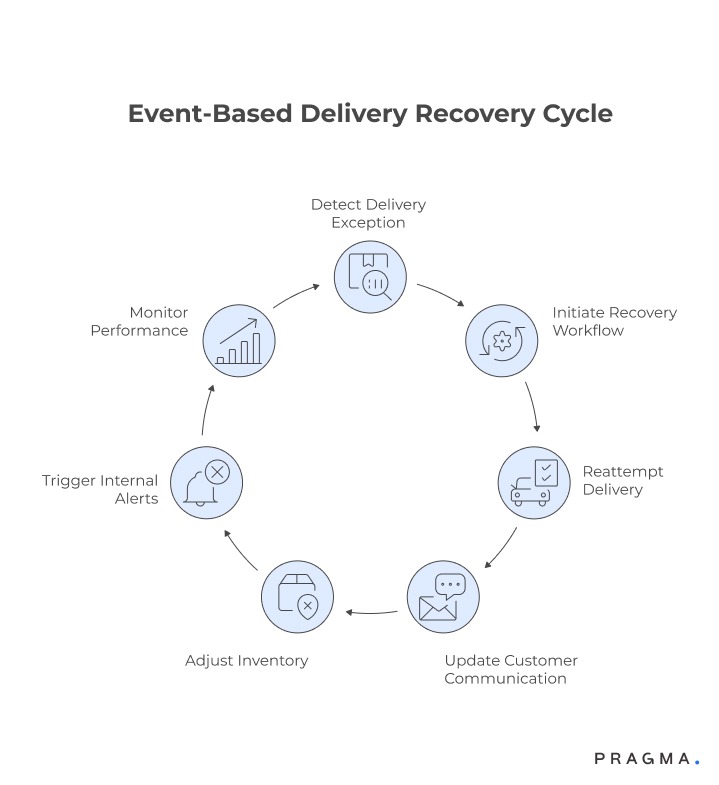
When a delivery exception is detected, a repeatable, well-defined workflow should dictate all next steps. This includes reattempting delivery, updating customer communication, adjusting inventory, and triggering internal alerts. Standardisation ensures consistent handling, prevents ad hoc decisions, and reduces delays caused by ambiguity.
Operational benefit
By mapping every event to a clear recovery path, ops teams can focus on high-priority interventions, minimise manual work, and track performance metrics systematically. This also enables better forecasting of resources during peak periods. For example, a first-attempt failure triggers a scheduled reattempt, customer alert, and warehouse notification automatically.
Automated notifications and triggers
Automating notifications for every delivery exception is critical. Customers and internal teams should be updated in real time through SMS, email, in-app notifications, or ops dashboards.
Detailed example
- First-attempt delivery failure: system sends customer SMS with next reattempt window, updates courier with priority schedule, and logs the event for warehouse ops.
- RTO initiated: customer notified immediately about package return, ops team alerted for rerouting or refund initiation.
Automating these notifications reduces manual follow-ups, keeps customers informed, and prevents support escalations.
Leveraging real-time data for smarter exception recovery
How data visibility improves decision-making and reduces recovery time
Delivery exception recovery becomes significantly more effective when powered by real-time data. Without accurate and timely inputs, even well-designed event-based templates can fall short due to delayed actions or incorrect prioritisation.
Real-time tracking integration
Operations teams must integrate courier tracking APIs directly into their systems to receive live updates on shipment status. This ensures that exceptions such as delays, failed attempts, or lost parcels are detected instantly rather than hours later.
With real-time visibility, workflows can trigger the moment an exception occurs—reducing lag between detection and action. For example, a delay flagged at a transit hub can immediately trigger a customer notification and internal escalation instead of waiting for end-of-day reports.
Data-driven prioritisation
Not all delivery exceptions require the same response speed or intensity. By combining order data (value, SKU type, location, customer history) with real-time logistics updates, teams can dynamically prioritise recovery actions.
For instance:
- A repeat customer with high lifetime value experiencing a delay can be prioritised for proactive outreach.
- A fragile item stuck in transit may trigger immediate intervention with the courier partner.
This level of intelligence ensures resources are allocated where they matter most, rather than following rigid workflows.
Operational dashboards for visibility
Centralised dashboards that display live exception data across regions, courier partners, and order categories enable faster decision-making. Ops leaders can quickly identify spikes in failures, underperforming courier lanes, or recurring delay patterns.
These insights not only improve immediate recovery but also inform long-term logistics optimisation. Over time, this reduces the frequency of exceptions themselves.
Outcome
By embedding real-time data into event-based templates, brands shift from reactive workflows to predictive and adaptive recovery systems—improving both efficiency and customer satisfaction.
Cross-team handoffs for exception resolution
Ensuring clarity, accountability, and fast resolution across ops, support, and logistics
Clear ownership at each stage
Each step in the recovery journey should define which team is responsible:
- Courier coordination: ensures packages are rerouted or reattempted.
- Customer communication: proactively informs buyers of status and options.
- Inventory adjustments: triggers replacement or refund workflows.
- Exception closure: confirms resolution in dashboards for reporting.
Operational clarity
Clear role definitions prevent tasks from slipping through the cracks. For example, if a first-attempt failure occurs, the ops dashboard immediately shows which team owns the retry, and support sees the same status for proactive outreach.
Integration with support channels
Support teams must have real-time visibility into exceptions to assist customers efficiently. Integrating event-based templates with CRM or ticketing systems ensures that agents can respond proactively rather than reactively.
Example
A high-value order flagged as lost triggers:
- Automatic alert in support dashboards
- Customer receives direct communication with next steps
- Ops team escalates for replacement
This prevents repeated customer inquiries and improves trust while keeping workflows structured.
Prioritising exceptions based on impact
Efficiently allocating operational resources to high-value orders
High-value and fragile items
High-value, fragile, or time-sensitive products must follow accelerated recovery workflows with escalation alerts and manual intervention if needed.
Operational workflow
- Immediate system alerts to ops and support teams
- Direct customer communication explaining next steps
- Reroute or replacement scheduled immediately
This ensures minimal revenue loss and maintains customer confidence.
Low-value or non-critical orders
Exceptions affecting low-value parcels can follow standard templates with automated notifications. Ops teams can focus resources on high-priority issues, while routine exceptions are resolved with minimal manual work.
Operational benefit
Automating low-impact exceptions reduces workload, speeds up recovery, and allows scaling during peak volumes without compromising service for premium orders.
Event-based journey template example
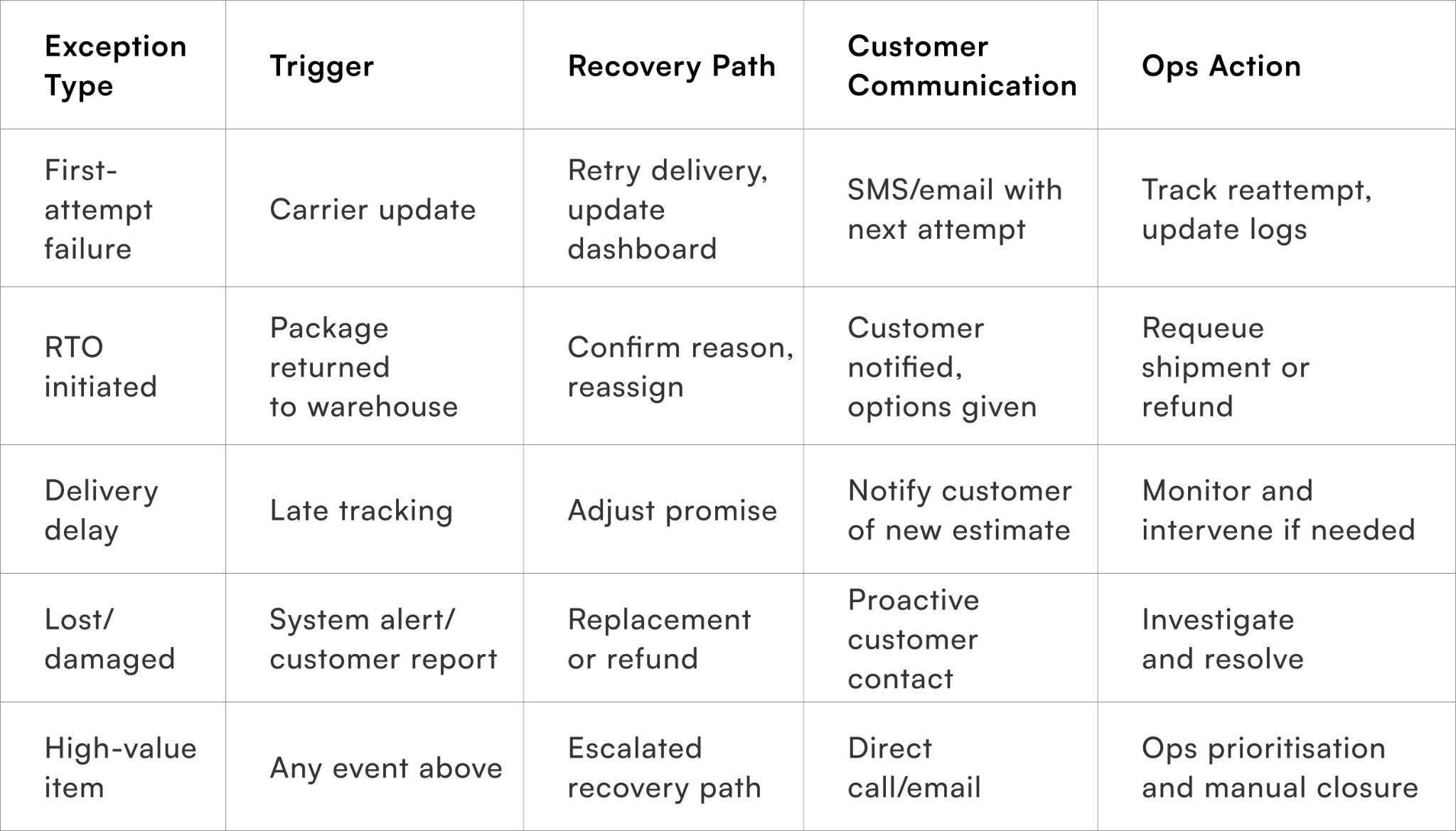
Building feedback loops to continuously improve recovery workflows
Turning delivery exceptions into operational intelligence
Event-based journey templates should not remain static. The most efficient D2C operations treat every delivery exception as a learning opportunity to refine workflows, improve courier performance, and enhance customer communication.
Capturing post-resolution insights
Once an exception is resolved, it is critical to log not just the event, but the outcome. This includes:
- Time taken to resolve
- Number of intervention steps required
- Customer response (complaint, satisfaction, repeat order behaviour)
This data helps identify whether the recovery workflow was effective or needs adjustment.
Identifying recurring failure patterns
Over time, patterns begin to emerge across delivery exceptions. Certain courier partners may show higher failure rates in specific pin codes, or certain product categories may consistently face damage issues.
By analysing these trends, ops teams can take preventive actions such as:
- Switching courier partners in high-risk zones
- Improving packaging for fragile SKUs
- Adjusting delivery promises based on historical reliability
This reduces dependency on recovery by preventing exceptions upfront.
Refining automation logic
Feedback loops also help fine-tune automation rules. For example:
- If customers frequently respond negatively to delayed notifications, communication timing can be adjusted earlier.
- If reattempt success rates are low after first-attempt failures, workflows can include customer confirmation before retrying delivery.
Continuous optimisation ensures that templates evolve with changing operational realities and customer expectations.
Cross-functional learning
Insights from delivery exceptions should not remain siloed within operations. Sharing learnings with customer support, marketing, and product teams creates a more aligned organisation.
For instance, marketing teams can adjust campaign promises based on delivery reliability, while product teams can redesign packaging based on damage reports.
Outcome
Strong feedback loops transform event-based recovery from a reactive necessity into a strategic advantage. Brands not only resolve exceptions faster but also reduce their occurrence over time—leading to better margins, smoother operations, and stronger customer trust.
Quick Wins on implementing event-based journeys
Step-by-step improvements for delivery exception recovery
Week 1 – Audit common delivery exceptions
Compile historical delivery exceptions, classify by type, impact, and affected customer segments. Identify patterns and recurring issues to prioritise automation and escalation rules.
Week 2 – Define event triggers and standardised templates
Map each exception to a workflow with clearly assigned ownership, expected timelines, and automated notifications. Include variations for high-value, fragile, or time-sensitive orders.
Week 3 – Implement automation for notifications and recovery steps
Automate SMS/email updates, reattempt scheduling, and ops dashboard alerts. Ensure workflows integrate with CRM and warehouse management systems.
Week 4 – Monitor, optimise, and scale
Track resolution times, customer complaints, RTO rates, and high-value exception handling. Adjust event thresholds, escalation rules, and automation logic for continuous improvement.
Metrics to track for delivery-exception recovery
Measuring operational efficiency and customer impact
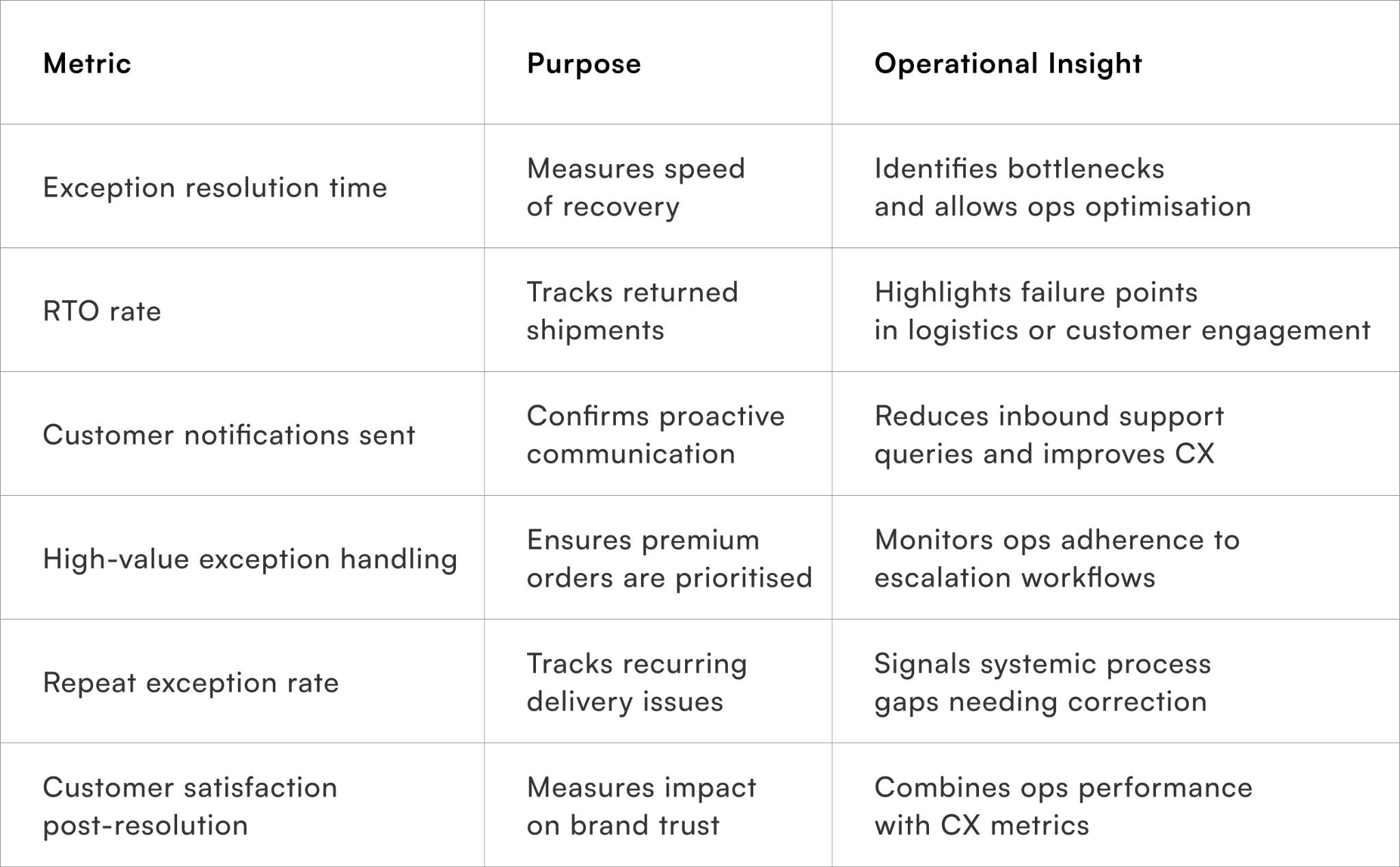
Tracking these metrics ensures timely intervention, operational visibility, and improved customer trust across all exception types.
To Wrap It Up
Event-based delivery-exception templates transform recovery from reactive firefighting to proactive, measurable workflows. By logging every exception, automating notifications, defining ownership, and prioritising high-impact orders, brands reduce RTOs, improve resolution speed, and maintain customer trust.
This week, audit recurring delivery exceptions and implement standardised event triggers with automated notifications for first-attempt failures and RTOs.
Long-term, continuously refine templates, track operational metrics, and integrate cross-team visibility to scale recovery processes efficiently.
For D2C brands seeking seamless delivery exception recovery, Pragma’s orchestration platform provides automated journey templates, real-time alerts, and workflow monitoring that help teams resolve exceptions faster while maintaining customer satisfaction.
.gif)
FAQs (Frequently Asked Questions On Event-based journey templates for delivery-exception recovery)
1. What is an event-based delivery-exception template?
A standardised workflow that maps delivery exceptions to predefined operational and customer-facing actions.
2. Which exceptions should trigger automated recovery?
First-attempt failures, RTOs, delivery delays, lost or damaged packages, and high-value item incidents.
3. How does automation improve recovery speed?
Automated notifications, reattempt scheduling, and ops dashboard alerts reduce manual interventions and prevent delayed responses.
4. How are high-value orders prioritised?
Templates escalate high-value, fragile, or time-sensitive orders to ops and support teams for immediate intervention.
5. What benefits do event-based templates provide to operations and CX?
They standardise responses, reduce manual firefighting, improve resolution times, maintain customer trust, and provide measurable insights for continuous improvement.
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo

.png)