

Carrier decisions quietly shape delivery speed, cost, and customer trust, yet in many D2C operations they are still driven by static rules or last-year averages. A carrier that performs well for one product or region can fail badly for another, especially during sales spikes or seasonal shifts. When these nuances are ignored, brands pay the price through SLA misses, higher RTOs, and avoidable escalations.
Carrier recommendation engine: inputs, weighting and feedback loop design looks at how D2C teams can move beyond manual carrier selection to a system that learns from real delivery outcomes. Instead of relying on a single score or headline metric, it focuses on combining multiple operational signals — product traits, pincode behaviour, time windows, and historical performance — into a dynamic recommendation.
The real advantage comes not just from better initial selection, but from continuous correction. By feeding delivery results back into the engine, teams can adapt to changing conditions, improve accuracy over time, and ensure carrier choices remain aligned with business priorities rather than outdated assumptions.
What inputs should a carrier recommendation engine actually use?
Choosing signals that reflect real delivery performance
Why order-level attributes matter more than generic carrier scores
Most carrier selection logic starts and ends with overall performance metrics like average TAT or delivery success rate. While useful, these aggregates hide important variation. The same carrier can perform very differently depending on what is being shipped, where it is going, and when it moves through the network.
Order-level attributes such as product category, fragility, COD vs prepaid, shipment value, and promised delivery window provide far more predictive power.
For example, a carrier optimised for low-cost apparel COD deliveries may underperform on high-value electronics or fragile items. Ignoring these distinctions leads to systematic mismatches.
How product attributes influence carrier suitability
Weight, dimensions, fragility, and packaging constraints often determine whether a carrier can reliably deliver without damage or delay.
How does pincode-level data improve recommendation accuracy?
Local performance beats national averages
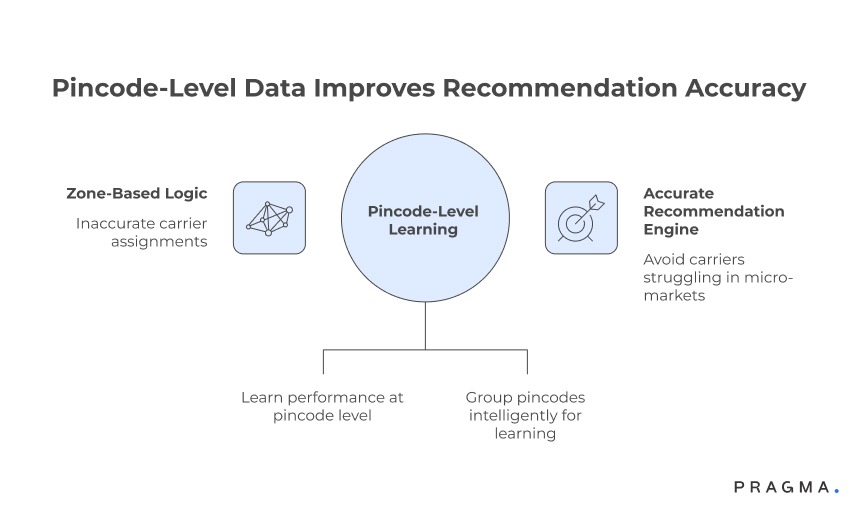
Moving from zone-based logic to micro-market signals
Many teams still assign carriers using broad zones or regions. In practice, delivery outcomes vary sharply even between neighbouring pincodes due to hub capacity, last-mile partners, or access constraints.
A recommendation engine becomes significantly more accurate when it learns performance at the pincode or cluster level.
Pincode-level metrics such as first-attempt success, average delivery time, NDR frequency, and RTO rates help the system avoid carriers that consistently struggle in specific micro-markets — even if their national numbers look strong.
Why sparse data should not block pincode learning
Where volume is low, pincodes can be grouped intelligently based on geography, urbanisation, or hub mapping to retain signal without overfitting.
What role does time and period play in carrier selection?
Performance is not static across the calendar
Accounting for seasonality, sales, and capacity stress
Carrier performance is highly sensitive to time. The same carrier may deliver reliably during steady weeks but degrade sharply during sale periods, festivals, or weather disruptions. A robust recommendation engine treats time as a first-class input, not a footnote.
Incorporating period-based signals — such as sale vs non-sale days, weekday vs weekend, or peak-hour cut-offs — allows the engine to anticipate congestion rather than react after failures occur.
Using recent performance windows without overreacting
Short-term spikes should influence recommendations, but safeguards are needed to prevent knee-jerk switches caused by temporary anomalies.
Which operational signals add value — and which don’t?
Separating useful inputs from noise

Prioritising outcome-linked metrics over vanity indicators
Not every available data point deserves equal weight. Metrics that directly reflect customer and SLA impact — delivery success, attempt quality, delay recovery — consistently outperform softer indicators like scan frequency or self-reported carrier SLAs.
High-quality engines focus on signals that correlate with final outcomes, even if those signals are fewer in number. This keeps models interpretable and operationally trustworthy.
Why more inputs can sometimes reduce accuracy
Adding weak or redundant signals increases complexity without improving decisions, making recommendations harder to explain and harder to tune.
How should data quality and freshness be handled?
Bad inputs lead to confident but wrong recommendations
Balancing historical depth with real-time relevance
Older data provides stability, but stale performance can mislead the engine in fast-changing environments.
Effective systems blend longer-term baselines with recent performance snapshots, ensuring recommendations reflect current conditions without being overly volatile.
Clear data hygiene rules — handling missing scans, delayed updates, or inconsistent carrier feeds — are essential. Without them, weighting logic becomes meaningless.
Why explainability matters for ops adoption
When teams understand why a carrier was recommended, they are more likely to trust and follow the system, even during exceptions.
How should different inputs be weighted without overfitting the model?
Balancing stability with responsiveness in carrier decisions
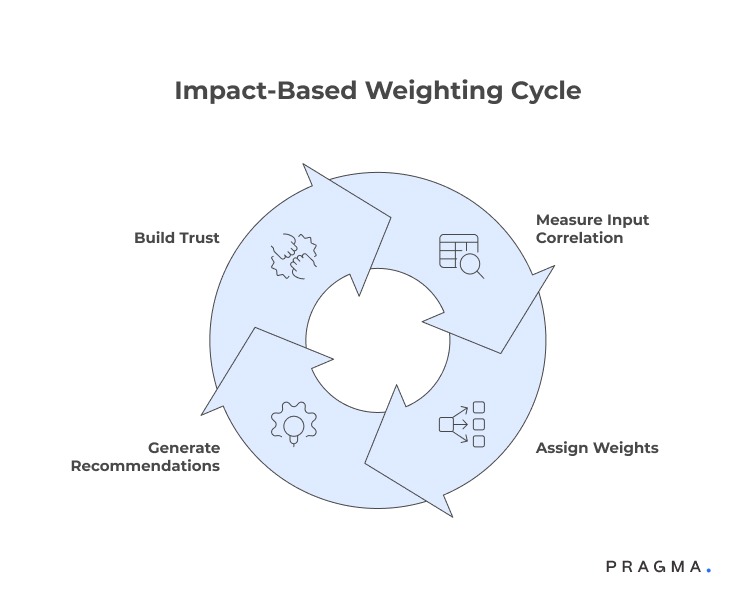
Moving from equal weights to impact-based weighting
A common mistake in early carrier engines is treating all inputs as equally important. In reality, some signals have a far stronger relationship with outcomes than others. For example, pincode-level delivery success often predicts performance better than national averages, while product fragility may outweigh minor cost differences.
Impact-based weighting starts by measuring how strongly each input correlates with final outcomes such as on-time delivery, RTO, or damage rates. Inputs with consistent, outcome-linked influence should carry more weight, whilst weaker signals are either down-weighted or removed.
Why transparent weighting builds operational trust
When ops teams can see that high-impact factors dominate recommendations, they are far more likely to rely on the engine instead of overriding it manually.
How can weighting adapt to changing conditions over time?
Avoiding rigid models in dynamic logistics environments
Using rolling windows instead of static scores
Carrier performance shifts with capacity, staffing, and external disruptions. Static weights based on long historical periods quickly become outdated. A more resilient approach blends long-term baselines with recent rolling windows, allowing the engine to adapt without becoming erratic.
Recent performance should influence recommendations gradually, not instantly. This avoids oscillation where carriers are repeatedly promoted and demoted due to short-lived spikes or dips.
Preventing knee-jerk carrier switching
Introducing minimum stability periods or dampening factors ensures the system responds to sustained trends rather than temporary noise.
What does an effective feedback loop actually look like?
Turning delivery outcomes into learning signals
Closing the loop from recommendation to result
A recommendation engine only improves if it learns from what happens next. Every shipment should feed back outcomes — delivery success, delays, NDR reasons, returns — into the system. Crucially, the feedback must be tied to the context of the original recommendation.
This allows the engine to evaluate not just carrier performance, but decision quality: did the chosen carrier outperform alternatives for that specific product, pincode, and period?
Why feedback must be outcome-focused
Inputs like scan frequency matter less than final results. Feedback loops should prioritise end-state signals that reflect customer experience and SLA adherence.
How do you stop feedback loops from amplifying bias?
Learning without reinforcing bad assumptions
Ensuring exploration alongside optimisation
If the engine always selects the top-ranked carrier, it never learns whether alternatives could perform better under certain conditions. Introducing controlled exploration — limited volume testing of secondary carriers — prevents the model from locking into suboptimal patterns.
This approach is especially important when entering new regions, launching new products, or onboarding new carriers.
Using guardrails to protect service quality
Exploration should be capped and monitored, ensuring experimentation never jeopardises high-value or time-critical orders.
How should carrier recommendations be evaluated internally?
Measuring decision quality, not just outcomes
Tracking lift versus baseline logic
To justify trust in the engine, teams should compare its recommendations against previous rule-based or manual selection methods. Metrics like SLA improvement, RTO reduction, and cost-to-serve changes help quantify impact.
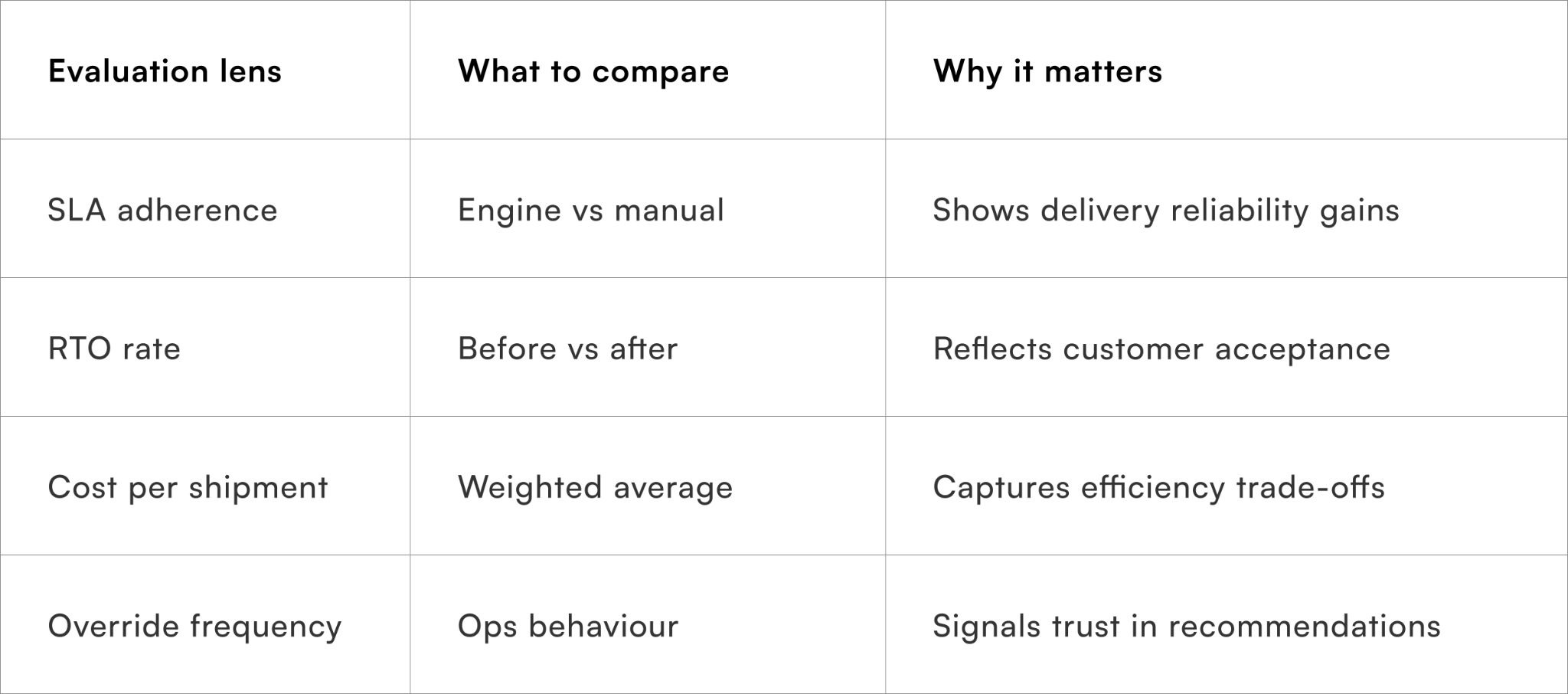
Why override analysis is critical
Frequent overrides often indicate missing inputs or mis-weighted signals, not ops resistance.
Quick Wins on implementation of recommended carrier engine inputs
Practical steps to launch a usable carrier recommendation engine
Week 1: Audit current carrier decisions and outcomes
List the top carriers used by product category and pincode. Map recent delivery outcomes against these decisions to identify obvious mismatches.
By the end of the week, teams usually uncover 2–3 high-impact segments where carrier choice is clearly misaligned.
Week 2: Define a minimum viable input set
Select a small, high-signal input set — product category, pincode cluster, payment type, and recent delivery success. Avoid adding optional or weak signals at this stage.
This keeps early recommendations interpretable and easy to validate.
Week 3: Introduce simple weighting and monitor overrides
Apply basic impact-based weights and surface recommendations alongside current rules. Track when teams override the engine and capture the reasons.
Override patterns quickly reveal missing signals or incorrect assumptions.
Week 4: Close the feedback loop
Ensure delivery outcomes flow back into the system with context. Begin adjusting weights based on sustained trends, not single events.
At the end of 30 days, most teams see measurable improvement in SLA consistency.
Metrics that indicate a healthy recommendation engine
Tracking decision quality, not just delivery outcomes
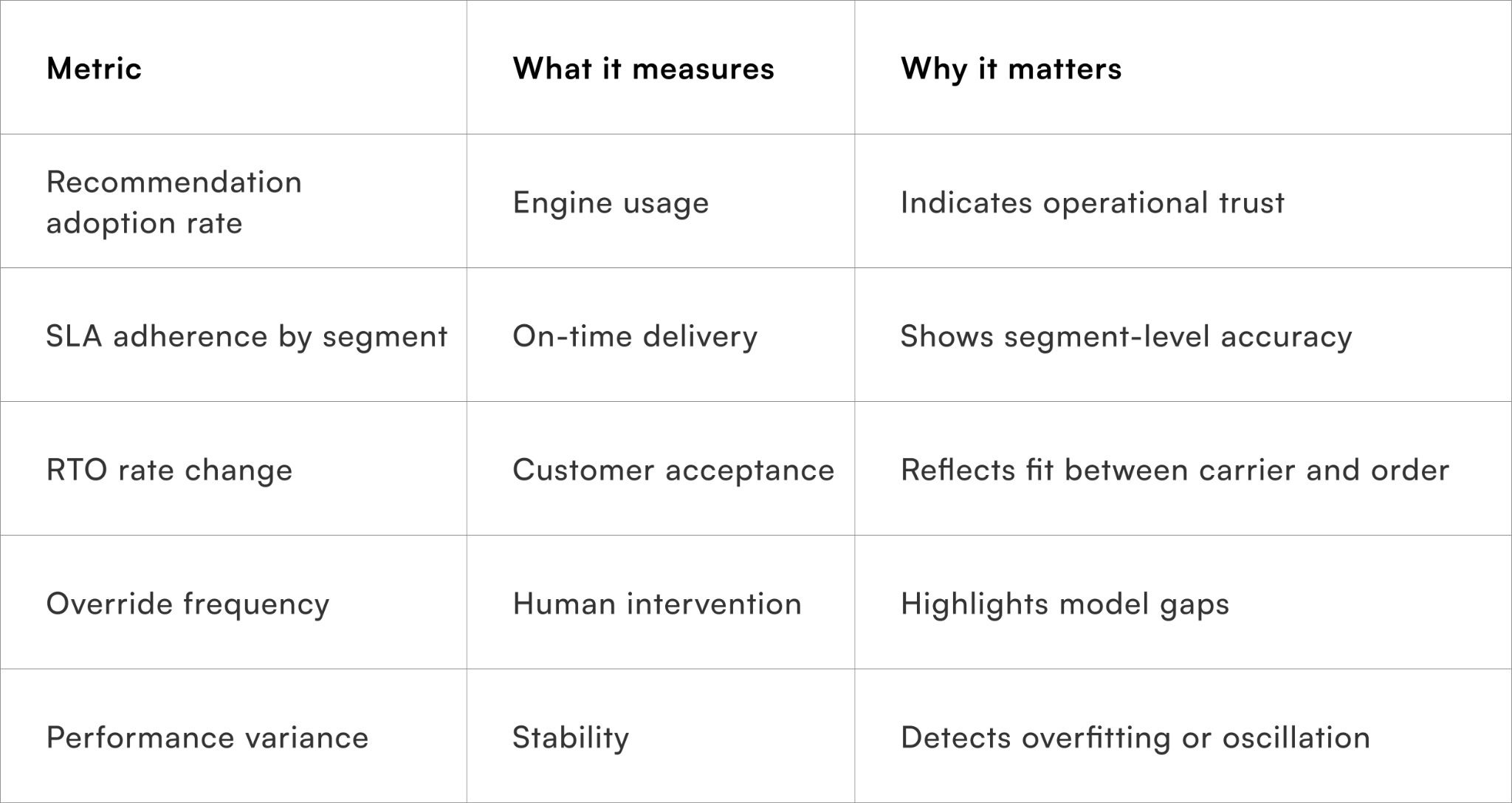
These metrics ensure the engine is improving decisions, not simply reacting to past failures.
To Wrap It Up
A carrier recommendation engine delivers value only when it reflects real operational complexity rather than abstract averages. The combination of the right inputs, thoughtful weighting, and a disciplined feedback loop enables more reliable delivery outcomes without constant manual intervention.
This week, identify one product–pincode segment where carrier choice is clearly underperforming and pilot a weighted recommendation instead of fixed rules.
Over time, continuously reviewing inputs, weights, and feedback ensures the engine adapts to changing conditions while remaining stable and explainable.
For D2C brands seeking adaptive carrier selection at scale Pragma’s orchestration platform provides contextual recommendations, outcome-driven learning, and decision transparency that help brands improve SLA adherence and reduce RTOs across regions.
.gif)
FAQs (Frequently Asked Questions On Carrier recommendation engine: inputs, weighting and feedback loop design)
1. What is a carrier recommendation engine?
A carrier recommendation engine selects the best delivery partner using data-driven rules and predictive models.
It optimises cost, speed, and delivery success rates.
2. What inputs are required for a carrier recommendation engine?
Inputs include shipment details, pincode performance, SLA data, costs, and historical delivery outcomes.
Accurate inputs improve recommendation quality.
3. How are weights assigned in the recommendation model?
Weights are assigned based on business priorities such as cost, speed, and reliability.
They determine how each factor influences the final carrier selection.
4. Why is weighting important in carrier selection?
Weighting ensures the engine aligns with operational goals and customer expectations.
It balances trade-offs between cost efficiency and service quality.
5. What role does historical data play in the engine?
Historical data helps identify carrier performance trends across regions and shipment types.
It improves prediction accuracy and decision-making.
6. How does the feedback loop improve recommendations?
The feedback loop updates the model using actual delivery outcomes and performance metrics.
This enables continuous learning and optimisation.
7. What metrics are used in the feedback loop?
Common metrics include delivery success rate, transit time, RTO rate, and SLA compliance.
These metrics refine future carrier recommendations.
8. Can the engine adapt to real-time changes?
Yes, it can incorporate real-time data such as delays, capacity issues, or disruptions.
This ensures more responsive and accurate decisions.
9. How does the engine reduce delivery failures?
It selects carriers with better performance for specific routes and shipment types.
This lowers failure rates and improves customer satisfaction.
10. Is automation necessary for a carrier recommendation engine?
Automation enables real-time processing and scalability across large shipment volumes.
It reduces manual intervention and decision errors.
11. How can businesses implement a carrier recommendation engine?
They need integrated data systems, defined business rules, and machine learning models. Continuous monitoring and tuning ensure long-term effectiveness.
Talk to our experts for a customised solution that can maximise your sales funnel
Book a demo


.png)